Annotation Tools and Beyond
Introduction
I will mainly talk about the technical details of an open source project Chinese Annotator I’ve been working on and some thoughts around it. Before that, I’d like to emphasize the context of why we need such annotation tools.
Why Annotation Tools
Most machine learning problems are supervised learning. Be it recommendation systems, image recognition or natural language processing, we all probably need label data for building good models and making correct predictions.
In some lucky cases, such label datasets are automatically generated. For example, in recommendation systems, people natrually generate label data by clicking on an ad on the webpage, adding stuff in their shopping cart on Amazon, or listening to songs on Spotify.
In some other cases, we can find smart tricks to generate label data. For example, when we want to build an named entity recognition or relation extraction model from the text, we can actually follow the so called “Distant Supervision” idea by crawling entity and relation data from the internet and using them to train the model. Though such data may be noisy, we find some deep learning models quite robust.
However, there can be cases when neither automatically generated label data nor smart tricks are available. This is when we need annotation tools to help us generate label data efficiently.
There are already quite some image recognition annotation tools out there, for example labelme from MIT.

There are also tons of companies offering human labor for generating label data. For example there are lots of commercial “human captcha recognition” services in China for crawling need, and even Amazon has their Mechanical Turk human labelling service which they call “Human intelligence through an API”.
You can imagine that there are many cases where not all the data can be easily shared with those commercial services. First problem is data privacy. As the most valuable asset , data cannot simply be given away by the companies. Second problem is the lack of expert knowledge. Some labelling task requires deep expert knowledge to make a judge on the labels, and such is not always suitable for outsourcing the task.
This is where we need annotation tools that are easy to deploy, intuitive to use, and effective to generate label data.
Annotator for Chinese Text Corpus
Most tasks in Natural Language Processing are supervised learning problem. There are sequence labelling problems such as Part-of-Speed Tagging, Tokenization and Named Entity Recognition, classification problems such as relation extraction, sentiment analysis and intention recognition. All those problems need label data for training the model. With deep learning conquering almost all the areas, DL based NLP models are especially data thirsty.
Situation is better for English language. Many large-scale corpora are out there for people to research on such as SQuAD Reading Comprehension corpus from Stanford. For Chinese, such open source corpus is way less, making it quite difficult to transfer the state-of-art technologies developed with English to Chinese. On the other hand, for some vertical context such as health, finance, legal and public security, there are bunch of special entities and needs. We cannot use general models trained on google news or Wikipedia dump in those special contexts.
Traditional annotation methods are complex and clumsy. We have to label multiple times for “Swiss Re”, “Swiss Reinsurance” and “Swiss Re Group”. Such process needs large amount of repetitive human labors.
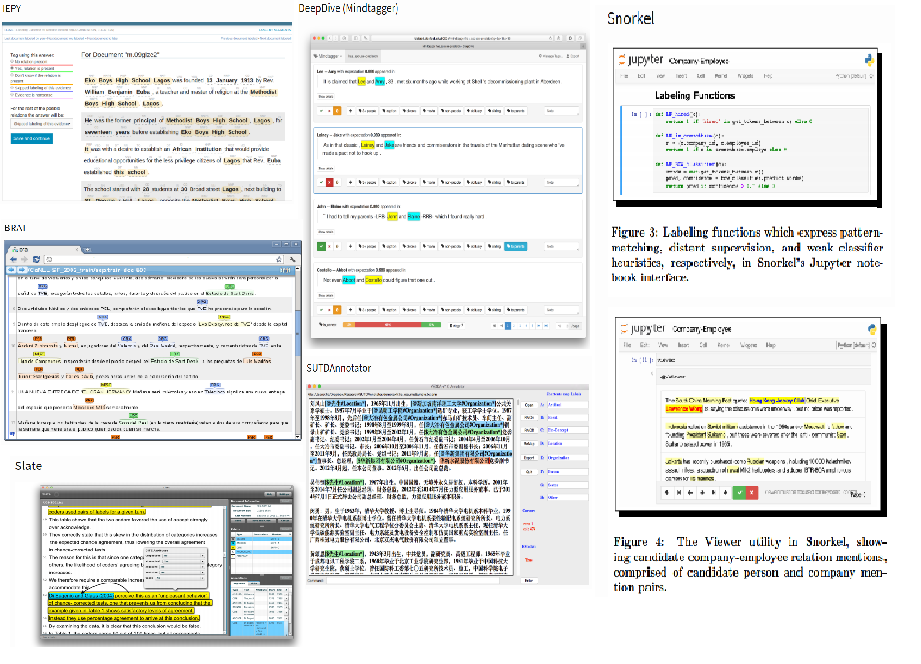
There are already many other text corpus annotation tools like IEPY, DeepDive (Mindtagger), BRAT, SUTDAnnotator, Snorkel, Slate and Prodigy, but those are either not open source, only supporting English, using outdated software technology, not able to be easily configured or modified, or very difficult to use.
Annotation Tools
Can we build a Chinese text annotator, so that
-
Labelling process has intelligent algorithms behind it so that we minimize human labor.
-
Labelling UI is friendly, intuitive and easy to use.
The answer must be yes.
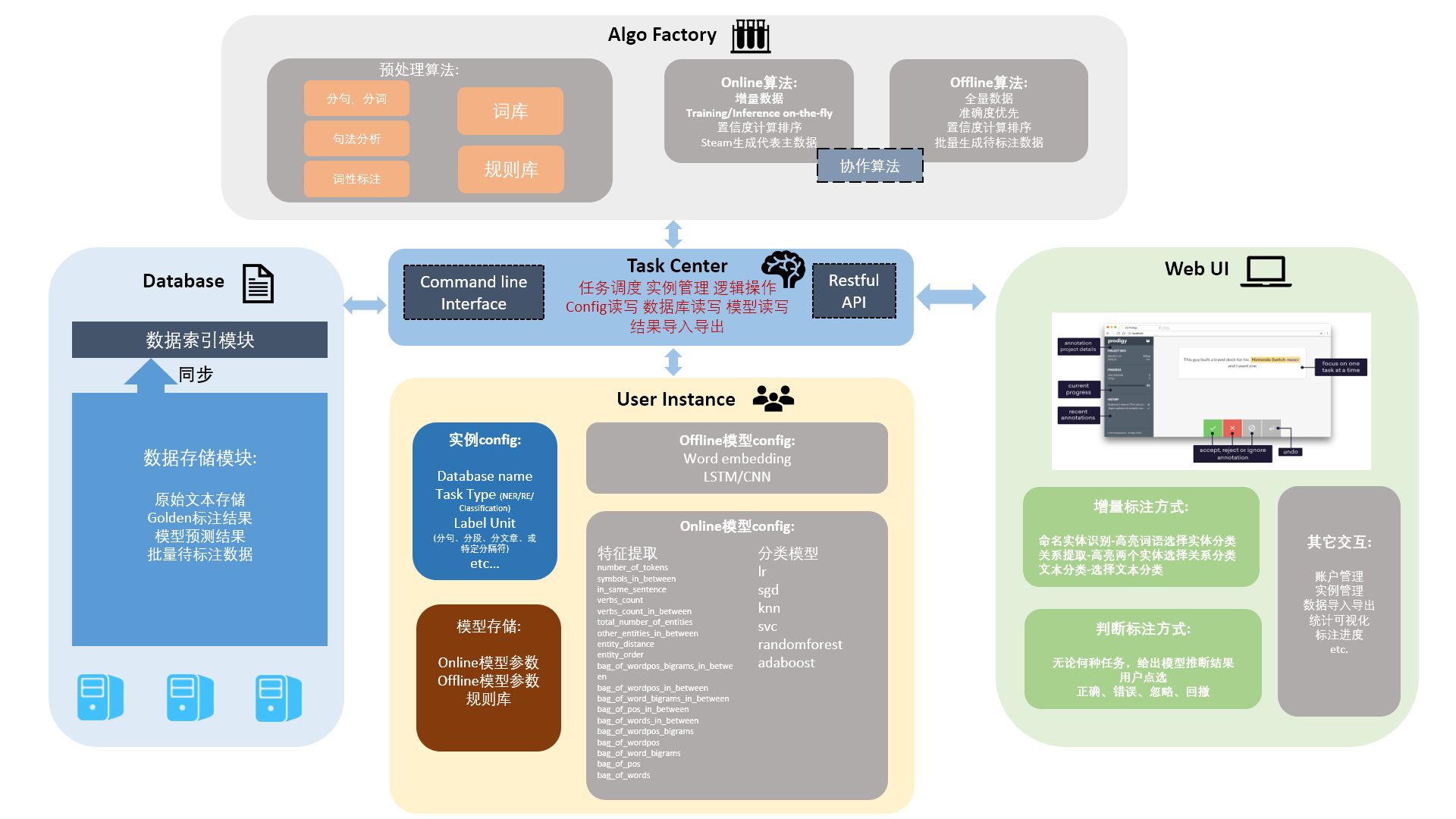
Intelligent Labelling with Active learning
.
├── config # System config files
├── docs # Documentations
├── tests # Test cases
│ └── data # Raw data for tests
├── chi_annotator # Main project folder
│ ├── algo_factory # Algo Factory module containing general algorithms
│ ├── preprocess # Preprocess codes
│ ├── online # Online Algorithms for Active Learning (svm for now)
│ └── offline # Offline Algorithms for higher Accuracy (DL models)
│ ├── task_center # Task Center module (main entrance and logic control)
│ ├── webui # WebUI module
│ ├── apis
│ └── static
│ ├── data # Database module
│ └── user_instance # User Instance module holding config files for specific tasks
│ └── examples # User Instance examples
| ├── classify # Text Classfication
| ├── ner # Named Entity Recognition
| ├── pos_tagger # POS Tagger
| └── re # Relation Extraction
└── ...
Process:
-
Users make labels
-
Backend active learning algorithm will consist of “Online” part and “Offline” part. “Online” part will do the online learning and update online model in real time, using fast traditional algorithms like SVM and BoW; When label data is accumulated to a certain amount, “Offline” part will update the offline model, using highly accurate deep learning models.
-
After model is updated, we will do as much prediction as possible (with regard to annotation timeline and computing resources), rank the confidence, and choose the certain number of samples with lowest confidence as datasets waiting to be labeled. Repeat step 1.
Frontend Design
Hopefully the process will ignore data with highest confidence, and focus on the low confidence samples that lies on the classification boundaries. Such algorithm will help reduce the human labor during labelling work.
Online and Offline models will work with each other, and evolve with human labelling process; After we finish enough labelling samples we will retrain the offline model with all the hand-labelled “golden” samples to achieve best results.
Data Pipeline and Modular Design
We must make very clear about how data flows within the labelling and active learning process. For different tasks different algorithms and data flows will be used. Such data pipeline requires a highly modular and configurable design of the system.
Modular Design
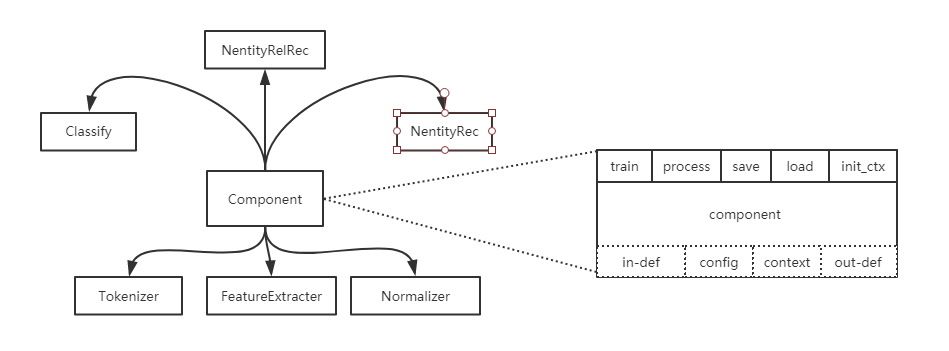
Data Pipeline
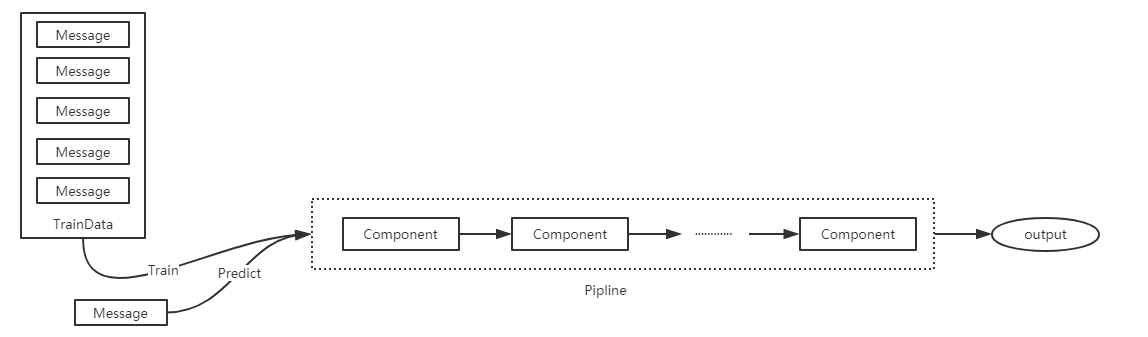
For example, Database module can be plugged with mySQL, sqlite, MongoDB or any other databases with a proper API; Restful API is used for exchanging data between WebUI module and backend, so users choose to use the provided WebUI or simply replace it with their own user interface, or even use scripts to implement more sophisticated functions; Algo Factory contains a bunch of different preprocessing functions, classification and sequence labelling algorithms for users to connect into an algorithm pipeline.
Configurations are simple json files. An example is shown below:
{
"ip" : "localhost",
"port": "8000",
"database_type": "mongodb",
"type": "classification"
"name": "email_spam_classification",
"model_type" : "classification",
"pipeline": ["nlp_word2vec",
"linesplit_preprocess",
"feature_extractor",
"online_svm_classifier_sklearn",
"offline_svm_classifier_sklearn"],
"language": "zh",
"wordvec_file": "./tests/data/test_embedding/vec.txt",
"path" : "./tests/models",
"org_data" : "./tests/data/test_email_classify/email_classify_chi.txt",
"database_name" : "spam_emails_chi",
"labels": ["spam","notspam"],
"batch_num" : "10",
"inference_num" : "20",
"low_conf_num" : "10",
"confidence_threshold" : "0.95",
"log_level": "INFO",
"log_file": null
}
I won’t get into details about the implementations, but such design is quite common for machine learning projects. Similar modular and data pipeline design can be found extensively in Rasa(chatbot), SpaCy(NLP), IEPY(annotation), Scikit-Learn(machine learning) and Tensorflow(deep learning). If you think about it, even the whole python community is based on such configurable modular design.
More than an Annotation Tool
Such a software is actually beyond just an annotation tool.
We have the Data Manager that handles the storage and exchange of raw data, pre-processed data, feature engineered data, labelled data and predicted data. We can even add upstream modules like crawlers or downstream modules like visualizations.
We have the Model Manager that handles different versions of configured, pre-trained, online, offline and persisted models. Such models, after careful validation, can be packaged a Prediction Service that opens unlimited possibilities.
At end of the day, this project will hopefully be a Full Pipeline Machine Learning Tool.
One More Thing
The core team Chinese Annotator has around 10 people consisting of full stack hackers, algorithm experts and professional software engineers, all of which are volunteering from the internet, scattered in Chengdu, Shanghai, Nanjing, Beijing, Guangzhou, Shenzhen and Hong Kong.
We started from a vague idea, went through white board design, software architecture diagrams, choice of stack for back and front end, configurable and pluggable algorithm design, unit testing cases and more. As of today (Feb.22 2018) on GitHub we have more than 30k lines of codes, 153 commits, 248 stars, 76 forks, 14 issues and 41 pull requests.
There is no actual reward for such open source work, but team members have been actively self-organizing discussions, sharing of resources, learning from each other and collaboratively coding.
We use WeChat and GitHub for communications, and started using Asana for project management. We chat on WeChat, persist ideas in GitHub issues, allocate and claim tasks, setting deadlines, synchronize progress, sharing resources and discussing specific tasks on Asana. We later also set up GitHub wiki for better document organizing, pytest for unit testing, Travis-CI for continuous integration, gitter chatroom to encourage more public discussion (from developers and end-users) and more.
GitHub Wiki
Asana
Travis-ci
Gitter
I’d like to call such working style Distributed Asynchronous Collaboration. There is no compulsory meetings, and we try out best not to influence daily job and personal time. Members will mute all the messages until personally available. We have only one WeChat voice meeting every week, each lasting less than 30 minute. Such asynchronous communication is relaxing and efficient. I was worried that distributed collaboration may not work. However, what happened was team members raising pull request at mid-night, and me reviewing and merging codes on the subway. This is the beauty of Distributed Asynchronous Collaboration: Flat and Transparent, Spontaneous Collaboration, and Full Trust and Support for Human Nature.
Is this a better way of running projects? Companies will save money from renting expensive office at downtown, and can recruit talents without restrictions from locations. There will be less traffic jam and air pollution.
Employees are scattered all around the world in sofas, cafes, libraries or anywhere with good quality WIFI, avoiding meaningless long commute. We can choose the best living and working place for ourselves. We can spend time with our children. We can go swimming, grab a coffee or even travel around the world while working. Our sense of achievement is fulfilled not from sitting in the office for 8 hours, but from implementing and delivering good projects. Everybody is trusted by default. Personal programming workload and performance can be carefully quantified and awarded, and everybody should be happy and efficient as long as they claim and deliver their tasks.
Distributed Asynchronous Collaboration will make a better world, and I strongly believe this will be the future of industries like software engineering and data science.
Reference
-
This article intends to be an English re-writing of my previous two blogs 构想:中文文本标注工具 and 分布式异步协作让世界更美好. I’m re-writing in English for sharing with my international colleagues at Swiss Re as well as to the English speaking community.
-
Swiss Re “Own the Way you Work” Publication http://www.swissre.com/publications/Own_the_way_you_work.html
-
A curated list of awesome remote jobs and resources. https://github.com/lukasz-madon/awesome-remote-job
-
WordPress Remote Working Culture:https://whenihavetime.com/2014/07/08/10-lessons-from-4-years-working-remotely/
-
Github Remote Working Culture:https://zachholman.com/posts/how-github-works/
-
TED Talk about Stanford Professor Nicholas Bloom doing experiment with Ctrip Shanghai on Qorking from Home:https://ideas.ted.com/why-working-from-home-should-be-standard-practice/