浅谈垂直领域的chatbot
chatbot是这一两年最火的话题,是自然语言处理“王冠上的钻石”。chatbot本身是一个很难的问题,商业与技术上套路都貌似飘忽不定。这篇博客我们试图理清思路,简单聊聊垂直领域的主要是任务导向的客服性质的chatbot。至于开放的偏娱乐性的陪聊机器人,如小黄鸡和小冰等,严肃如我暂且略过不谈。
文章仅代表个人看法,学识和视野都有限,欢迎讨论欢迎拍砖。
确定要用chatbot?
在探讨技术前,面对手头的需求我们应该先问问自己:真的需要上chatbot吗?
香港的麦当劳这两年大规模上线了自动点餐系统。一排大触摸屏,几个夸张的大按钮,多种支付方式,几个步骤就买到心仪的套餐。数码港的麦当劳现在只剩下一个大妈把守的聊天柜台,大部分顾客都去用触摸屏了。

如这种目标单一明确、步骤逻辑清晰的交互场景,如电影购票、飞机火车订票、宾馆房间预订、买咖啡买外卖等等(虽然很多被用来做chatbot发论文的使用场景),chatbot并不见得是个比触屏和按钮更好的选择。
chatbot要代替的更应该是这样一类场景:垂直领域的客服系统,用户产生大量相似的疑问和需求,目标明确或半明确且可能需要引导;而客服(chatbot)具有领域专业知识(知识图谱)与丰富问答经验(问答历史数据),可以在几分钟内解决用户问题和需求;机器chatbot解决不掉的,再扔给人工客服。很多场景可能最频繁的前十个问题已经能解决大部分用户通用的问题,而chatbot的优势在于可以自动化获取用户画像、快速读取海量相关知识库、通过多轮对话快速给出针对用户需求的个性化答案。
类似的场景,如医院科室咨询、商品售后服务、淘宝客服、证券投资咨询、银行业务办理等等。这些场景真正落地和解决的感觉还不多,任重而道远。
传统chatbot架构
早期的chatbot架构,主要是基于模板和规则,如AIML(Artificial Intelligence Markup Language)。
一个简单的带前端的AIML chatbot可以参考 https://github.com/crownpku/aiml_chatbot
我们简单给出一段AIML的查询天气的模板例子,感受一下规则系统:
<?xml version="1.0" encoding="UTF-8"?>
<aiml version="1.0">
<category>
<pattern>*</pattern>
<that>你现在在什么地方</that>
<template>
<think><set name="where"><formal><star/></formal></set></think>
<random>
<li><get name="where"/>是个好地方.</li>
<li>真希望我也在<get name="where"/>, 陪你.</li>
<li>我刚刚看了下<get name="where"/>的天气哦.</li>
</random>
</template>
</category>
<category>
<pattern>外面热么</pattern>
<template>
你现在在<get name="where"/>,
<system>python getweather.py realtime <get name="where"/></system>
</template>
</category>
<category>
<pattern>告诉我 * 天气</pattern>
<template>
<system>python getweather.py realtime <star /></system>
</template>
</category>
<category>
<pattern>* 现在天气</pattern>
<template>
<system>python getweather.py realtime <star /></system>
</template>
</category>
</aiml>
规则的描述主要基于正则表达式或者类似正则表达式的pattern。用户的问题match到这样的pattern上,从而取得template的答案结果。AIML本身有比较强大的描述能力,可以通过规则从用户问题中获取重要信息,可以随机选择备选答案,或者甚至run相应脚本通过外部API获取数据等等。事实上诸如AliceBot这样基于AIML的chatbot,拥有四万多个不同的category数据,即是一个海量的规则数据库。
使用规则的好处是准确率高。但是缺点也很明显:用户的句式千变万化,规则只能覆盖比较少的部分。仅仅像上面询问天气的例子,用户就可以有几百种的询问方法。而越写越多的规则也极其难维护,常常有可能会发生互相矛盾的规则,而往往一个业务逻辑的改动就要牵一发而动全身。
另一个方法是维护一个庞大的问答数据库,对用户的问题通过计算句子之间的相似度来寻找数据库中已有的最相近的问题来给出相应答案。之前在知乎和Quora赞助的一些比赛中有很多类似的问题,因为这些问答网站不希望用户提很多重复的问题,每一个新问题都会和已有问题做匹配;由此也产生了一些诸如skip-thought计算句向量等的方法。
当前主流的chatbot架构比较趋于统一,主要是模块化的三个部分:对用户问题做处理的自然语言理解模块,对当前对话状态和决定系统反应的对话管理模块,以及反馈给用户的自然语言生成模块。
Natural Language Understanding 自然语言理解
自然语言理解(NLU)模块,主要是对用户的问题在句子级别进行分类,明确意图识别(Intent Classification);同时在词级别找出用户问题中的关键实体,进行实体槽填充(Slot Filling)。一个简单的例子,用户问“我想吃羊肉泡馍”,NLU模块就可以识别出用户的意图是“寻找餐馆”,而关键实体是“羊肉泡馍”。有了意图和关键实体,就方便了后面对话管理模块进行后端数据库的查询或是有缺失信息而来继续多轮对话补全其它缺失的实体槽。
从自然语言处理和机器学习的角度看,意图识别是一个很传统的的文本分类问题,而实体槽填充也是一个很传统的命名实体识别问题。
两者都需要标注数据。我们举一个标注数据的例子,里面包含了”greet”, “affirm”, “restaurant_search”, “medical”等几种不同的意图;在”restaurant_search”又有”food”这种实体,而在”medical”中又有”disease”这种实体。实际中需要比这个多得多的标注数据才可以训练出可用的模型。
"common_examples": [
{
"text": "你好",
"intent": "greet",
"entities": []
},
{
"text": "早上好",
"intent": "greet",
"entities": []
},
{
"text": "对的",
"intent": "affirm",
"entities": []
},
{
"text": "确实",
"intent": "affirm",
"entities": []
},
{
"text": "找个吃拉面的店",
"intent": "restaurant_search",
"entities": [
{
"start": 3,
"end": 5,
"value": "拉面",
"entity": "food"
}
]
},
{
"text": "这附近哪里有吃麻辣烫的地方",
"intent": "restaurant_search",
"entities": [
{
"start": 7,
"end": 10,
"value": "麻辣烫",
"entity": "food"
}
]
},
{
"text": "我胃痛,该吃什么药?",
"intent": "medical",
"entities": [
{
"start": 1,
"end": 3,
"value": "胃痛",
"entity": "disease"
}
]
}]
看上去这和使用规则的AIML数据非常相像。然而我们实际用到的是这些标注数据训练出的更复杂的机器学习模型,其表现力和泛化能力将大大增强。列出了“拉面”和“麻辣烫”的例子,再出现“凉皮”、“糖葫芦”等词汇,一个好的NLU系统也会成功将他们也标识成为食物。
输入的文本,先要经过分句、分词、词性标注等基础自然语言预处理;对某些应用来讲指代消解也是非常重要的步骤,将原有的指代词甚至零指代补全成完整名称,可以消除很多NLU的歧义。
然后要进行特征处理和模型训练。传统上会有很多人工造出来的如”number_of_tokens”, “symbols_in_between”, “bag_of_words_in_between”等特征,然后通过Linear Classification, Support Vector Machines等传统的机器学习分类模型与HMM, CRF等传统的机器学习序列标注模型来做意图识别与实体识别。另一种方法是在大量语料上使用word2vec进行非监督训练,将词的特征隐含学习在词向量中,然后通过深度学习的模型来做意图识别与实体识别。
这里要特别提一下,word2vec和词向量的发明,将原来貌似只能one-hot encoding的词语变成了稠密、神秘、优美又表现力丰富的向量形式,使得自然语言处理一下从繁琐的语言学特征中跳出来,也一举推动深度学习在NLP领域中大展身手。这种表示学习(representation learning)的风潮,现在已经刮到了诸如知识图谱(graph embedding)和推荐系统(user embedding)的领域。我们在一个奇怪的训练语料上训练出的word2vec,通过词向量计算相似度就可以有以下的结果:
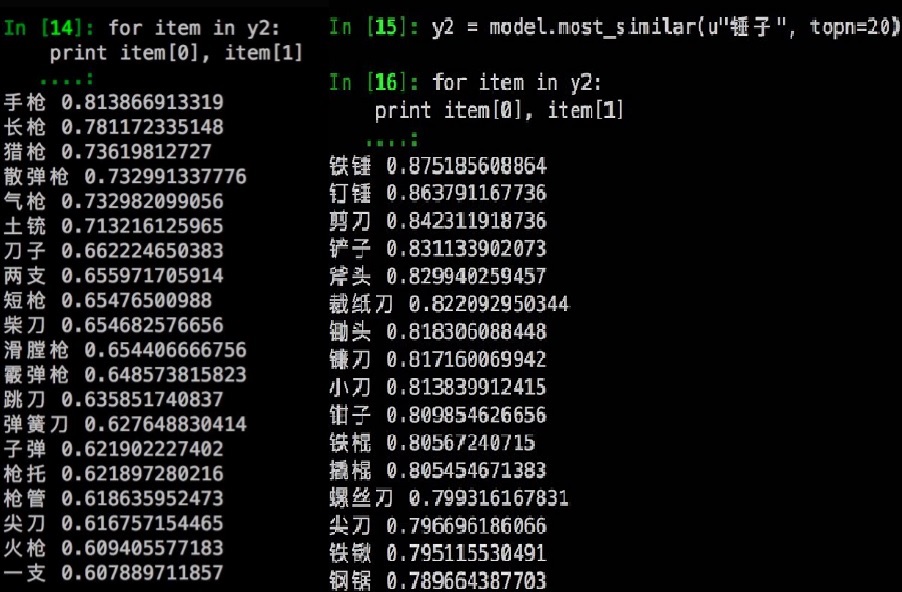
通过训练模型的方法,可以有比较高的recall,即可以覆盖更多不同的用户输入。同时我们也可以结合上面提到的规则模块,甚至将一些高precision的规则整合成为特征的一部分来帮助我们训练机器学习的模型。整个框架可以总结成下面的一幅图:
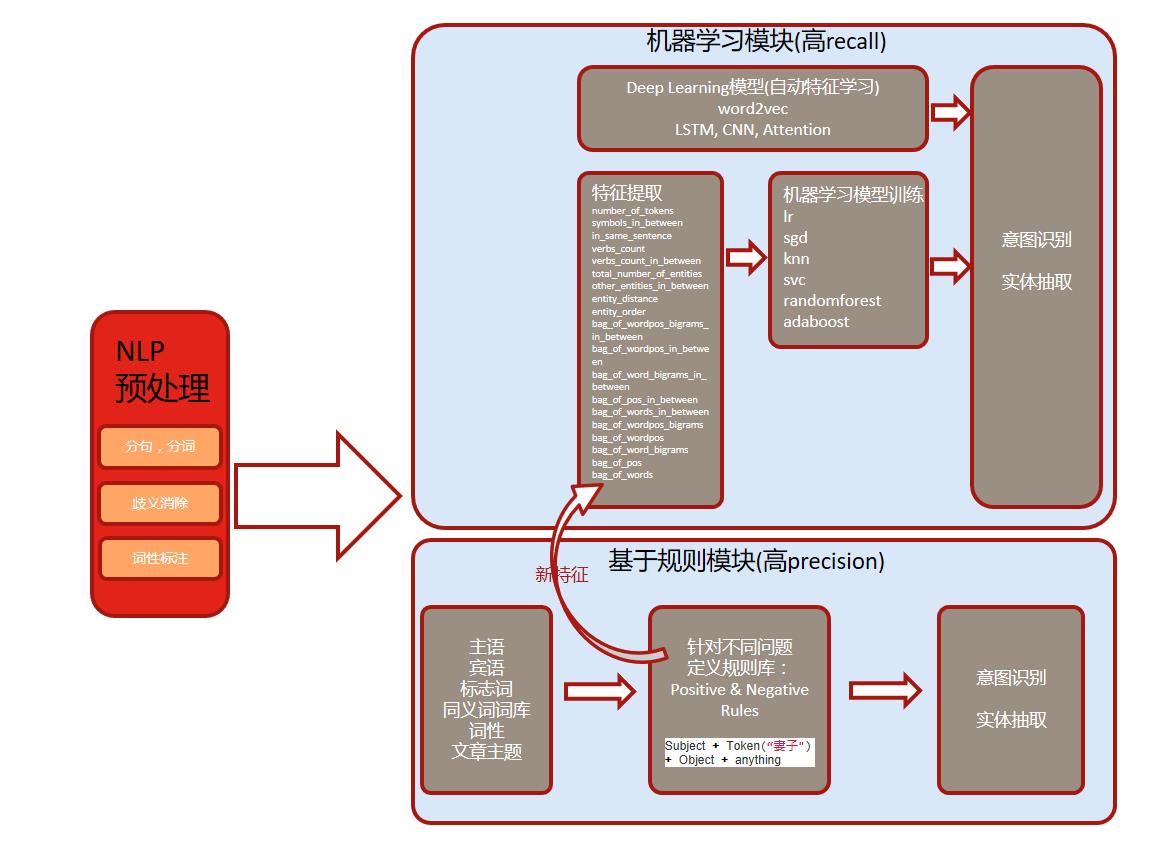
一个基于Rasa NLU的中文NLU开源系统可以参考 https://github.com/crownpku/rasa_nlu_chi
Dialogue Manager 对话管理
对话管理(DM)模块的首要任务是要负责管理整个对话的流程。通过对上下文的维护和解析,对话管理模块要决定用户提供的意图是否明确,以及实体槽的信息是否足够进行数据库查询或开始履行相应的任务。
当对话管理模块认为用户提供的信息不全或者模棱两可时,就要维护一个多轮对话的语境,不断引导式地去询问用户以得到更多的信息,或者提供不同的可能选项让用户选择。对话管理模块要存储和维护当前对话的状态、用户的历史行为、系统的历史行为、知识库中的可能结果等;当认为已经清楚得到了全部需要的信息后,对话管理模块就要将用户的查询变成相应的数据库查询语句去知识库(如知识图谱)中查询相应资料,或者实现和完成相应的任务(如购物下单,或是类似Siri拨打xx的电话,或是智能家居去拉起窗帘等)。
一个例子如下:
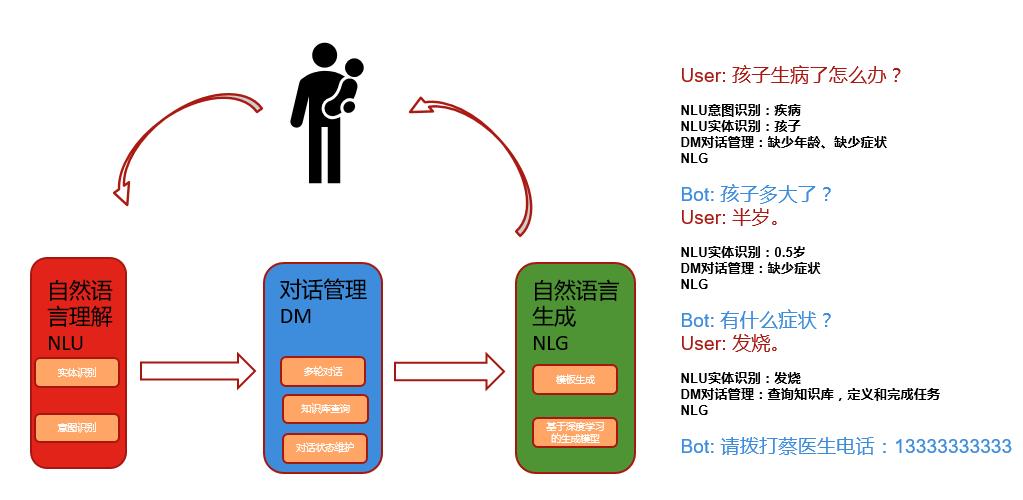
实际实现中,对话管理模块因为肩负着大量杂活的任务,是跟使用需求强绑定的,大部分使用规则系统,实现和维护都比较繁琐。比较新的研究中,有将对话管理的状态建模成为一个序列标注的监督学习问题,甚至有用强化学习(Reinforcement Learning),加入一个User Simulator来将对话管理训练成一个深度学习的模型。
Natural Language Generation 自然语言生成
自然语言生成(NLG)模块是机器与用户交互的最后一公里路。对于闲聊机器人来讲,往往在大量语料上用一个seq2seq的生成模型,直接生成反馈给用户的自然语言。然而这个模型的结果在垂直领域的以任务为目标的客服chatbot中往往不适用;客户需要的是准确的解决问题的答案,而不是汪峰style的歌词或者包含诗意的俏皮话;我们只能等未来有一天数据足够多、模型足够好,可以真正生成准确而以假乱真的自然语言。
在这之前,自然语言生成大部分使用的方法应该仍然是基于规则的模板填充,有点像实体槽提取的反向操作,将最终查询的结果嵌入到模板中生成回复。手动生成模板之余,也有用深度学习的生成模型通过数据自主学习生成带有实体槽的模板。
端到端的深度学习chatbot
深度学习大火的今天,也有很多尝试用DL做端到端的以任务为目标的chatbot的工作。
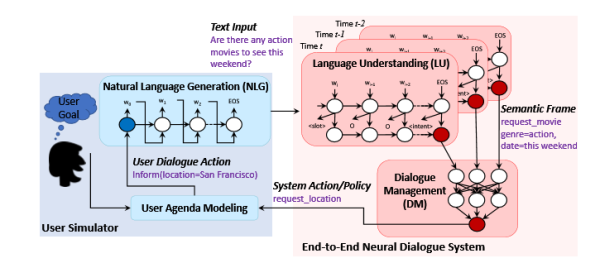
我所看到的这方面的工作,有一些是将上面提到的传统的chatbot架构,NLU+DM+NLG,每一个模块都换成DL模型,甚至再加入User Simulator做强化学习,进行端到端的训练。一个例子如下,图片来自 End-to-End Task-Completion Neural Dialogue Systems:
另外一些研究界非常火的工作是Memory Networks。这方面的工作偏向于seq2seq的方式,将整个知识库都encode在一个复杂的深度网络中,然后再和encode过的问题结合起来decode生成答案。这个工作最多还是应用在机器阅读理解上,最著名的是Stanford的SQuAD,而且有一些神乎其技的结果;而在垂直领域任务导向的chatbot上的成功应用还有待观察。
总结
-
老式chatbot基于大量规则库,不好维护
-
主流架构为”NLU自然语言理解+DM对话管理+NLG自然语言生成”
-
NLU负责基础自然语言处理,主要目标是意图识别与实体识别;DM负责对话状态维护、数据库查询等;NLG负责生成交互的自然语言
-
机器学习尤其是深度学习在不断改进NLU、DM和NLG,乃至对整个架构的颠覆