深度学习的正则健身计划
深度学习,和所有机器学习算法一样,也有着bias-variance的平衡问题。Bias是指模型基于不准确的假设而给出了错误答案,通常由于under-fit产生,模型的表达力还不够强大;Variance指模型由于训练数据中的小扰动过于敏感产生的错误,通常由于over-fit产生,模型太过复杂而失去了训练集以外数据的泛化能力。
深度学习的模型发展到今天,神经元层数越来越深不见底,层间连接也越来越走位飘忽。如此复杂的模型常常会陷入埋头炼丹多日却表现孱弱的尴尬局面。这里我们来简单总结下各路老中医怎样给神经网络用多种正则手段定制健身计划,让神经网络模型更健康,更强大。
本文所有的正则技巧都只是简单介绍,作者水平有限,欢迎大家补充和更正。一个稍微有点旧但是非常详尽的介绍,可以参考Goodfellow的Deep Learning相关章节。
Shared Weights
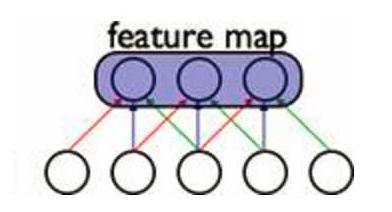
共享参数的方法,可以大大减少模型的参数规模。在CNN中,每一个filter的权重参数在扫过整张图片的时候都是保持一致的,这就可以学习出多种不同的特征提取器。在unfold之后的RNN中,所有前后时刻隐变量之间的权重参数保持一致,每个时刻的输入与隐变量之间的权重参数也保持一致,这样的特性使得RNN复杂度大大减少,可以处理任意长度的序列。
Early Stopping
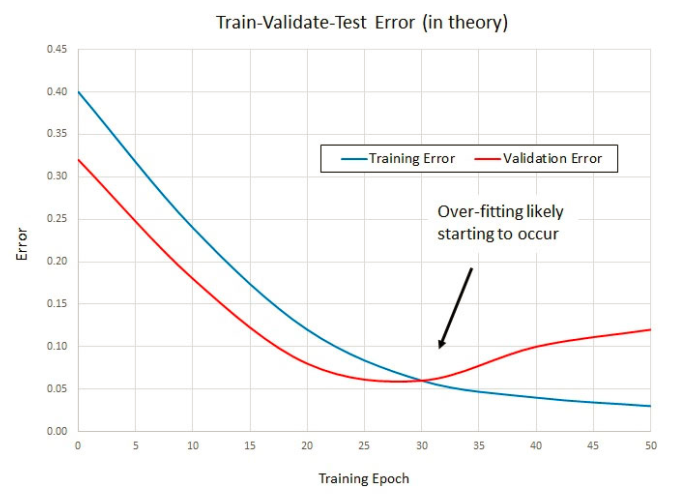
把机器学习的标注数据分为训练集、验证集和测试集是常识了吧~如果你的training data loss还在慢慢下降,而validation set loss已经好几个epoch木有降低了,那似乎可以停止训练了。
Dropout
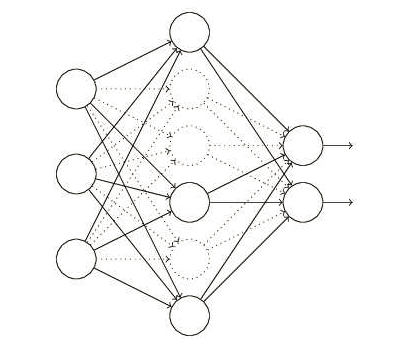
Dropout是指在训练过程中,每次训练都以一定几率随机“关闭”一些神经元和与之相关的连接;在预测过程中再把所神经元恢复。这样训练出来的模型,可以理解为是一堆不同结构神经网络的ensemble,使得网络更加鲁棒。
Dropout的技巧被发表之后就基本成为了大家训练模型的标配。比如就有吐槽说很多新论文中把有dropout的结果和旧论文中没有dropout的结果作了对比,却宣称是自己一些其它技巧带来的表现提升,很不公平。
# apply dropout before feed to lstm layer
model_inputs = tf.nn.dropout(embedding, self.dropout)
Batch Normalization
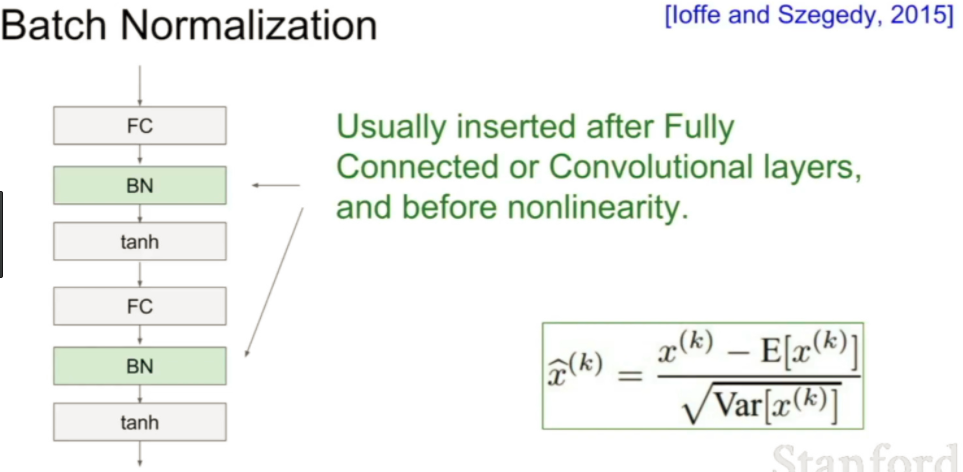
Batch Normalization也渐渐成为了训练深度学习模型的标配。对于每个mini-batch的数据进行统计分布的标准化,减少训练中不同样本的差异性,提高模型的泛化能力。
# apply batch normalization layer
h2 = tf.contrib.layers.batch_norm(h1,
center=True, scale=True,
is_training=phase,
scope='bn')
Gradient Clipping
这是对待exploding gradient问题最简单粗暴的方法:如果gradient大于某一个值,我们就强行将其限制在某一个范围内。
# apply grad clip to avoid gradient explosion
grads_vars = self.opt.compute_gradients(self.loss)
capped_grads_vars = [[tf.clip_by_value(g,
-self.config["clip"],
self.config["clip"]),
v]
for g, v in grads_vars]
self.train_op = self.opt.apply_gradients(capped_grads_vars, self.global_step)
L1 and L2 Norm on Weights

这是与传统机器学习一致的做法:在cost function中加入对权重的正则项,使得权重保持在合理范围之类。L2会让不重要的权重变成一个较小的值,而L1则会让不重要的权重最终变为0.
# apply l1 regularizer to total loss
total_loss = meansq #or other loss calcuation
l1_regularizer = tf.contrib.layers.l1_regularizer(
scale=0.005, scope=None
)
weights = tf.trainable_variables() # all vars of your graph
regularization_penalty = tf.contrib.layers.apply_regularization(l1_regularizer, weights)
regularized_loss = total_loss + regularization_penalty
train_step = tf.train.GradientDescentOptimizer(0.05).minimize(regularized_loss)
Dataset Augmentation

将同样的数据变出花来,大大增加训练数据量,这某种程度是将人类的先验知识也融入到训练数据之中。常见的在图像中会把图像翻转、灰度调整等等,而在NLP中会用一些同义近义词乃至语法规则来增加数据量。
以上是深度学习中我们常用的一些正则化技巧的简单介绍。使用这个正则健身计划,可以使深度学习模型更加健壮,心情开阔不走over-fit的极端,表现更加优异。
除去上面提到的正则化技巧,我们还会遇到过其它的一些正则方法,如Multi-task Learning, Sparse Representation, Bagging Ensemble, Adversarial Training等等。有兴趣的读者可以参考其它资料继续学习和实践,也欢迎留言讨论。