为什么保险行业需要联邦学习
联邦学习(Federated Learning)起源于谷歌2016年发表在NIPS的一篇文章[1]和2017年发表的博客[2]。其大意是谷歌要训练自家安卓系统的Gboard输入法模型,但又不希望把用户敏感的键盘数据上传到自家服务器(此处@搜狗)。与其让用户上传数据到云端服务器训练模型,谷歌选择让用户在自己的智能手机上单独训练一个模型(感谢各家芯片厂商的neural engine),然后把千万用户每个人的黑盒模型参数上传去谷歌的云端服务器进行融合,更新官方模型,然后再推送还给用户。这样一方面避免了用户敏感数据的传输和存储,一方面又利用了用户智能手机的计算能力(即是边缘计算edge computing)而大大减轻了中心服务器的计算压力。
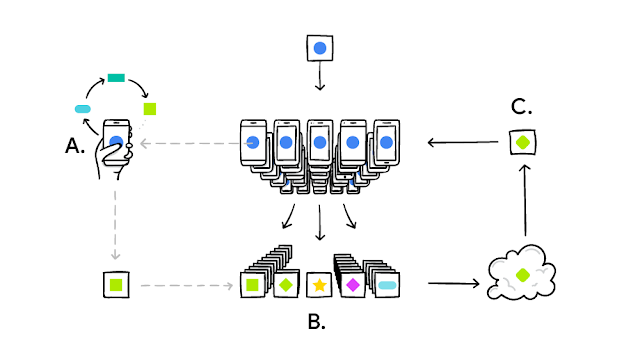
联邦学习的概念在发表的时候,谷歌虽然提到了数据隐私,但论文核心重点是模型如何在手机上传带宽受限的情况下进行传输,而用户模型的融合也只是用了简单有效的参数平均。这么做的原因是因为工程上类似的想法在分布式机器学习中已经被探讨了很多,slave-master结构被广泛采用,参数服务器大放异彩,模型参数以致训练过程中的梯度都可以在同步或非同步的方式下计算和传递。联邦学习的关注重点于是放在了没有严格分布式计算环境、上传带宽受限、海量用户作为slave下的“工程实现”。
随着社会对数据隐私的日益关注和政府越来越多相关政策的出台,正在疯狂积累数据和逐渐使用数据创造价值的企业们被数据合规的要求束缚了手脚;另一方面随着分工细化和市场竞争的加剧,同行业以致不同行业之间都虎视眈眈盯着对方盘子里的蛋糕而把自己的数据视若珍宝,数据孤岛妨碍了行业整体合作互利的可能性。大家都在寻找一个既能数据合规又能说服持份者合作共赢的彻底释放数据潜力的方法。这个时候联邦学习对数据隐私的作用就很快被人们认识到了,“联邦学习”这四个字也从一个谷歌产品的工程实现升级成为一个鼓励行业间数据分享共赢又尊重个体数据隐私的概念和解决方案。
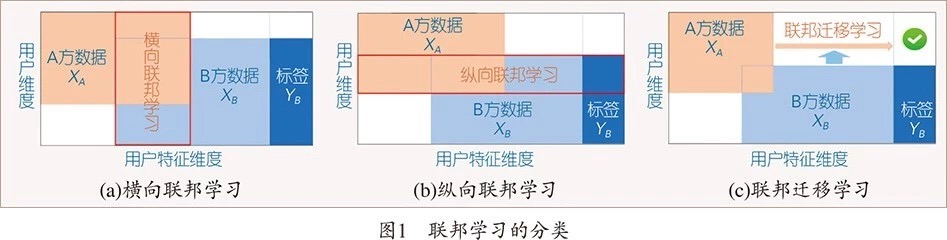
香港科技大学的杨强教授将联邦学习拓展分为三类:横向联邦学习,纵向联邦学习,以及联邦迁移学习[3][4]。横向联邦学习适用于特征重叠多而样本重叠少的情况下,这符合谷歌Gboard的使用场景,使用边缘模型的直接融合;纵向联邦学习适用于特征重叠少而样本重叠多的情况,使用场景如电商和银行两者有大量相同的用户但各自拥有不同用户维度的特征和标注,这时的做法既是将不同特征融合在一起,增加特征丰富度,但为了保护隐私和双方利益使用了加密技术;而联邦迁移学习是针对特征和样本重叠都少的情况,使用迁移学习来提升模型效果。这样的分类,从技术细节上看没有特别大的突破,模型融合、同态加密、迁移学习都是历史悠久的方向,但从实际应用上则拓展了联邦学习这个概念和其针对不同使用场景下的解决方案。
保险行业当前的一大痛点是数据。大部分保险产品可能用户量很大,用户数据维度也不错,但因为保险产品的性质,用户和保险公司的互动大多只在投保和赔偿时出现,交互频率低,保险公司标注数据的积累很少。保险公司的一个思路是尽力使用已有的如咨询、营销、投保、续保、赔偿等不同环节的结构或非结构化的用户数据,另一个思路是加大和用户的交互频率,将保险产品和IoT、车联网、智能手环、健身APP等建立连接。这些思路之外,不同保险公司以及保险公司和其它行业之间的数据分享将可能是下一个推进整个保险行业进步的方向。

保险作为一个几百年历史的传统行业,竞争异常激烈。如果你来香港最繁华的街头转一转,维港两岸的霓虹招牌很多都是各种保险公司的广告,你的朋友圈也可能时不时有香港朋友跳了反开始代理保险产品。这样情形下让保险公司互相分享数据就像是让牌桌上的所有人都亮出底牌和钱包。而联邦学习可能是解决问题的关键:在不亮底牌的情况下共建模型,分享数据红利,对营销、新产品开发、核保、定价、赔偿和用户体验等保险链条上的每一个环节进行优化,让牌桌上每个人的牌都变得更好,也让盘子里的钱越来越多。
联邦学习需要一个中心结点管理现有模型,接收边缘模型的参数,融合模型然后分发模型。这个中心结点很大可能会是再保险(Reinsurance)公司。
再保险公司是“保险公司的保险公司”,是B2B的生意。我们知道保险公司的盈利模式就是大数定理,“人人为我我为人人”。而在整个的保单组合上为了控制风险,直保公司会把相当一部分保单分保给再保险公司;而再保险公司的优势就是尽可能广的市场覆盖面和客户覆盖面,将不同地区不同直保公司的风险组合成一个全球范围内更可控的风险。一个地区的大事件,如911恐怖袭击或者天竹台风,可能对该地区一些的保险公司带来巨大风险;再保险大大减轻了这些直保公司的亏损压力,而再保险公司拥有着面对全球保险市场更大盘子的风险,又平摊了自己在某一个特定地区因为特定客户造成的风险亏损。
因为同患难共风雨了这么久,保险公司之间虽然竞争激烈,却都和再保险公司有着悠久的共赢互信的传统。很多保险公司面向终端用户的产品开发、核保、定价和赔偿决定,背后都有再保险公司的深度合作。如此背景之下,如果要建立起一个保险行业的联邦学习中心结点,再保险公司很可能是最合适的选择。
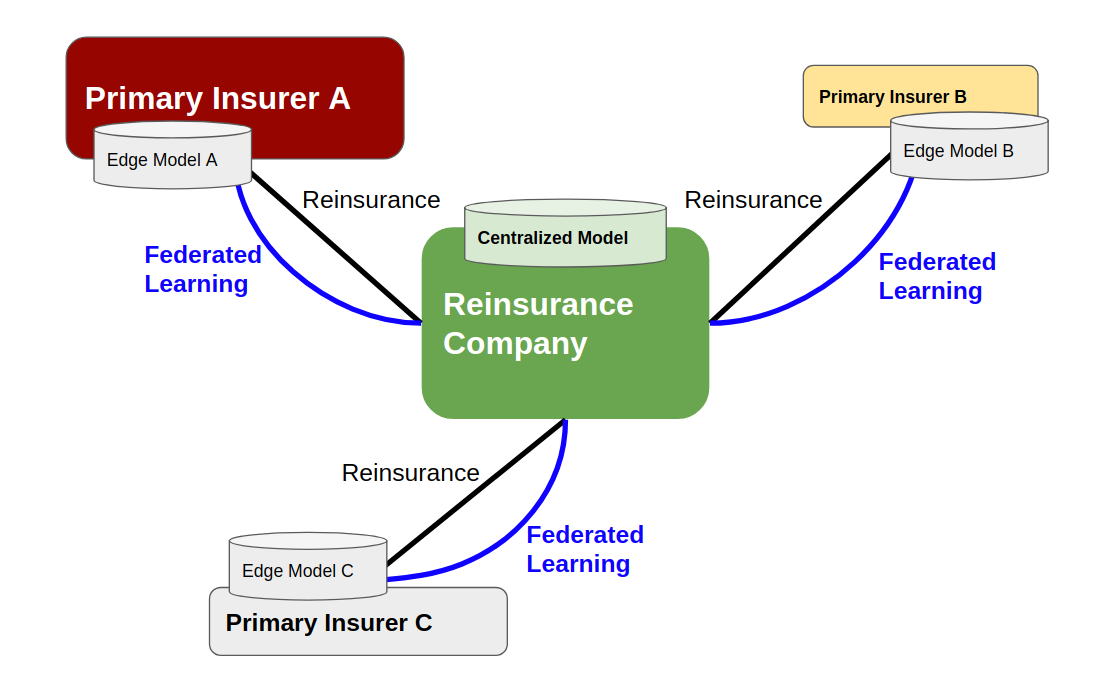
此时的合作方式应该是同谷歌类似的“横向联邦学习”。各个保险公司用自己的数据在自己的集群上训练模型,汇合到再保险公司;再保险公司进行模型融合调试后,再分发给保险公司。这在技术上更像是一个简单版本的联邦学习,因为直保公司不会如谷歌手机用户那么多,企业之间集群的通讯带宽也可以大大超过手机的数据带宽。此时联邦学习的重点意义就在于对终端保单持有人隐私的保护、对各个保险公司自有数据所有权的保护、以及对保险行业在数据和建模上合作共赢的推进。
一个值得注意的地方是,不同保险公司体量相差很大,所能提供的数据数量和质量差别也非常大。因此对参与联邦学习成员的激励机制也需要仔细考量。针对每个保险公司数据量和其对中心集成模型优化的贡献程度,进行差异化模型分发,或是直接进行再保险保费的差异化定价,都是激励保险公司参与联邦学习可能的方法。
笔者在一家再保险公司从事数据科学工作,很期待联邦学习能引起保险行业的关注,也欢迎和朋友们继续探讨联邦学习和其它人工智能技术在推动保险和金融科技方面的机会。
[1]”Federated Learning: Strategies for Improving Communication Efficiency”, https://pmpml.github.io/PMPML16/papers/PMPML16_paper_20.pdf
[2]”Federated Learning: Collaborative Machine Learning without Centralized Training Data”, https://ai.googleblog.com/2017/04/federated-learning-collaborative.html
[3]”能够保障安全隐私的大数据算法「联邦学习」到底是什么?”, https://www.chainnews.com/articles/769415855789.htm
[4] ”联邦学习”, 杨强、刘洋、陈天健、童咏昕, CCF, https://dl.ccf.org.cn/institude/institudeDetail?id=4150944238307328&from=groupmessage&isappinstalled=0