Why Insurance needs Federated Learning
What is Federated Learning?
Federated Learning originated from an academic paper in NIPS 2016 [1] and a follow-up blog [2] in 2017, both published by Google. The idea is that Google wants to train its own input method on its Android phones called “Gboard” but does not want to upload the sensitive keyboard data from their users to Google’s own servers. Rather than uploading user’s data and training models in the cloud, Google lets users train a separate model on their own smartphones (thanks to the neural engines from several chip manufacturers) and upload those black-box model parameters from each of their users to the cloud and merge the models, update the official centralized model, and push the model back to Google users. This not only avoids the transmission and storage of user’s sensitive personal data, but also utilize the computational power on the smartphones (a.k.a the concept of Edge Computing) and reduce the computation pressure from their centralized servers.
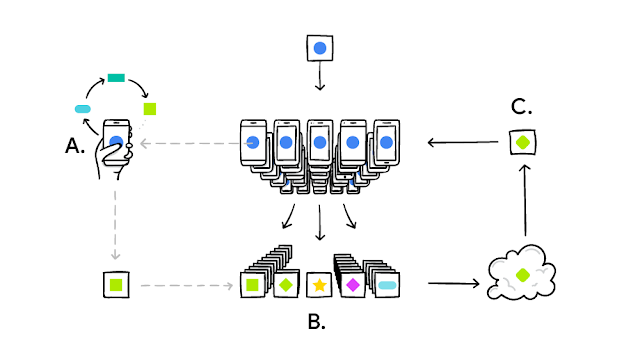
When the concept of Federated Learning was published, Google mentioned data privacy and utilized the the simple but effective parameter average for model ensembling, but the main focus was on the transmission of models as the upload bandwidth of mobile phones is usually very limited. One possible reason is that similar engineering ideas have been discussed intensively in Distributed Machine Learning. Slave-master structure is widely used and Parameter Server is so powerful that model parameters or even gradients during training process can be computed and shared synchronously or asynchronously. The focus of Federated Learning was thus on the “engineering work” with no rigorous distributed computing environment, limited upload bandwidth and slave nodes as massive number of users.
Can Federated Learning solve Data Privacy?
Data privacy is becoming a more and more important issue, and lots of relating regulations and laws have been taken into action by authorities and governments. The companies that have been accumulating tons of data and have just started to make value of it now have their hands tightened. On the other hand, market competition is increasingly intense and all companies value and secure their own data from sharing with the others. Information islands kill the possibility of cooperation and mutual benefit. Everyone is looking for a way to break such prisoner dilemma while complying with all the regulations. Federated Learning is soon being recognized as a great solution for encouraging corporation while respecting data privacy.
Professor YANG Qiang from The Hong Kong University of Science and Technology extends Federated Learning to three types: Horizontal Federated Learning, Vertical Federated Learning and Federated Transfer Learning [3][4]. Horizontal Federated Learning applies to circumstances where we have a lot of overlap on features but only a few on instances. This refers to the Google Gboard use case and models can be ensembled directly from the edge models. Vertical Federated Learning refers to where we have many overlapped instances but few overlapped features. An example is between banks and online-retailers. They both have lots of same users but each own their own features and labels data. Vertical Federated Learning merges the features together to create more powerful feature space for machine learning tasks, and uses homomorphic encryption to provide protection on data privacy. Federated Transfer Learning uses Transfer Learning to improve model performance when we have neither much overlap on features nor on instances. Model ensembling, homomorphic encryption and transfer learning are all well studied directions, but such categorization extends the concept of Federated Learning and clarify the specific solutions under different use cases.
So how can we apply Federated Learning to Insurance?
One pain point for insurance industry is label data. Most insurance products might already have lots of users and nice user features, since the interaction between user and insurer most happens only at insurance purchasing and claims insurer is not able to accumulate much label data with such low frequency of customer interaction. Insurers are trying their best to utilize all the structured and unstructured data they can get through the customer service, sales, underwriting, renewal and claims processes. They also try to connect their insurance product with IoT, telematics, smart watches and fitness apps etc. to increase the frequency of customer interaction. With all those trials, the next big thing to push the whole industry forward is very likely to be the sharing of data between insurers and companies from other industries.

As a traditional industry with hundreds of years of history, competition between insurance companies is fierce. If you visit Hong Kong, you will find so many billboards of different insurance companies on both sides of the Victoria Harbour. It would be like showing all your cards in the poker game to each other for insurers to share their own data. Federated Learning might be the key here: Insurers build models together without disclosing their data and share the benefit of machine learning by optimizing all across the business line from product development, underwriting, pricing to claim and user experiences. Everyone’s card will get better with more money on the table.
What’s the Role of Reinsurer?
Federated Learning needs a centralized node to manage the current models, get input from edge models, do the ensemble work and distribute it. This centralized node is very likely to be Reinsurance Companies.
Reinsurer is “the insurer for insurers”. This is a B2B business. We know the business model for insurers is the law of large numbers and “one for all and all for one”. To control risk for their policy portfolios, primary insurers will share some of their policies to reinsurers. The advantage of reinsurers is their wider coverage of markets and clients. They have a global business to hedge and pool on regional risks. One incident like earthquake or typhoon can bring great risk for insurers in the specific region and reinsurance will reduce the pressure of causing a big loss. On the other hand reinsurer has a larger portfolio across the globe and amortize the loss for a specific client in a specific region.
Primary insurers and reinsurers have been holding their hands for so long and they have great relationship and trust between each other. Cooperation between insurers and reinsurers is everywhere in the insurance business lines. If we want to build a central note for Federated Learning for insurance industry, reinsurance companies are most likely to be the choice.
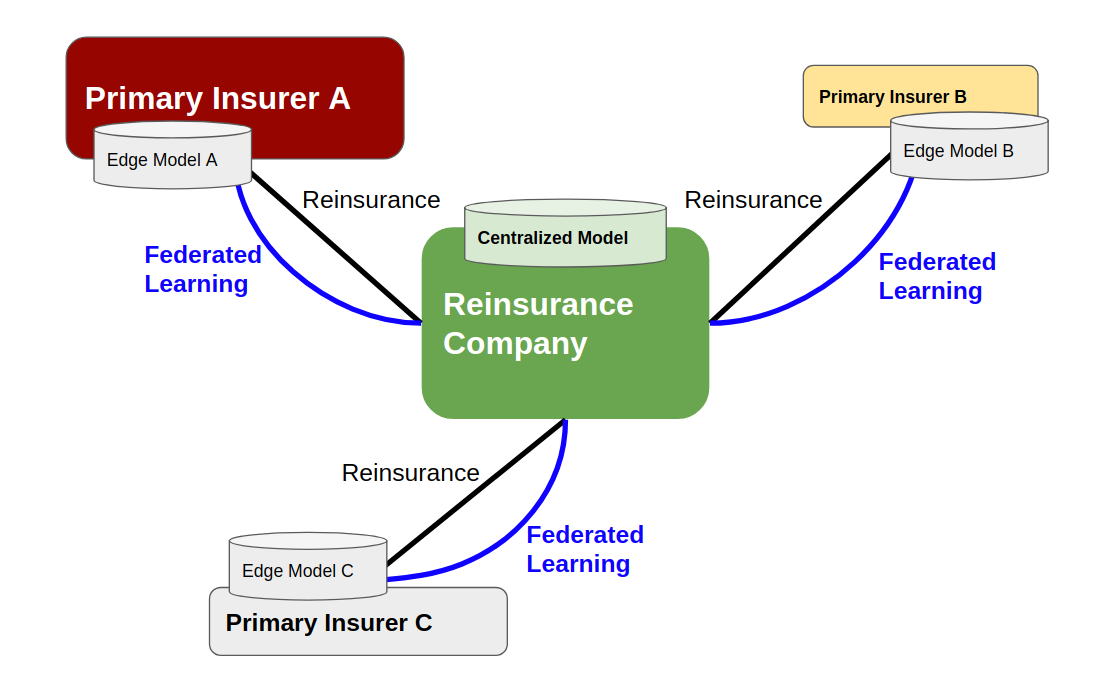
This should work as Horizontal Federated Learning just like Google’s Gboard. Each primary insurer trains their model with their own data on their own servers and upload the models to the reinsurance centralized node. Reinsurer ensembles the edge models to form up the “official” centralized model and distributes back to all the primary insurers. Technically this is like a simplified version of Federated Learning as number of insurers is way less than Google users and the communication bandwidth between enterprise servers can be much larger than the upload bandwidth of mobile phones. The focus of Federated Learning here will be privacy protection for policyholders, proprietary protection of data for each primary insurer and the mutual benefit for all insurers on data and modelling.
We have to also be very careful on the how to motivate each insurer to take part in the Federated Learning federation. The quantity and quality of data from each primary insurer can be very different. The reinsurer may distribute personalized models for each primary insurer or give personalized pricing for reinsurance premium according to their contribution to the centralized model.
The writer is working as Data Scientist at a reinsurance company. He is very keen to see the applications of Federated Learning for insurance industry.
[1] ”Federated Learning: Strategies for Improving Communication Efficiency”, https://pmpml.github.io/PMPML16/papers/PMPML16_paper_20.pdf
[2] ”Federated Learning: Collaborative Machine Learning without Centralized Training Data”, https://ai.googleblog.com/2017/04/federated-learning-collaborative.html
[3] ”能够保障安全隐私的大数据算法「联邦学习」到底是什么?”, https://www.chainnews.com/articles/769415855789.htm
[4] ”联邦学习”, 杨强、刘洋、陈天健、童咏昕, CCF, https://dl.ccf.org.cn/institude/institudeDetail?id=4150944238307328&from=groupmessage&isappinstalled=0