A Practical Overview of Federated Learning
Introduction
Federated Learning originated from an academic paper in NIPS 2016 [1] and a follow-up blog [2] in 2017, both published by Google. The idea is that Google wants to train its own input method on its Android phones called “Gboard” but does not want to upload the sensitive keyboard data from their users to Google’s own servers. Rather than uploading user’s data and training models in the cloud, Google lets users train a separate model on their own smartphones (thanks to the neural engines from several chip manufacturers) and upload those black-box model parameters from each of their users to the cloud and merge the models, update the official centralized model, and push the model back to Google users. This not only avoids the transmission and storage of user’s sensitive personal data, but also utilize the computational power on the smartphones (a.k.a the concept of Edge Computing) and reduce the computation pressure from their centralized servers.
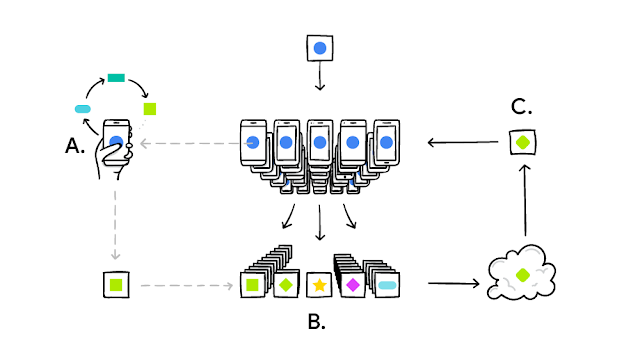
When the concept of Federated Learning was published, Google mentioned data privacy and utilized the simple but effective parameter average for model ensembling, but the main focus was on the transmission of models as the upload bandwidth of mobile phones is usually very limited. One possible reason is that similar engineering ideas have been discussed intensively in Distributed Machine Learning. Slave-master structure is widely used, and Parameter Server is so powerful that model parameters or even gradients during training process can be computed and shared synchronously or asynchronously. The focus of Federated Learning was thus on the “engineering work” with no rigorous distributed computing environment, limited upload bandwidth and slave nodes as massive number of users.
Data privacy is becoming a more and more important issue, and lots of relating regulations and laws have been taken into action by authorities and governments. The companies that have been accumulating tons of data and have just started to make value of it now have their hands tightened. On the other hand, market competition is increasingly intense and all companies value and secure their own data from sharing with the others. Information islands kill the possibility of cooperation and mutual benefit. Everyone is looking for a way to break such prisoner dilemma while complying with all the regulations. Federated Learning was soon recognized as a great solution for encouraging collaboration while respecting data privacy.
Categorization
Professor YANG Qiang from HKUST extends Federated Learning to three types: Horizontal Federated Learning, Vertical Federated Learning and Federated Transfer Learning [3][4]. Model ensembling, homomorphic encryption and transfer learning are all well studied directions, but such categorization extends the concept of Federated Learning and clarify the specific solutions under different use cases.
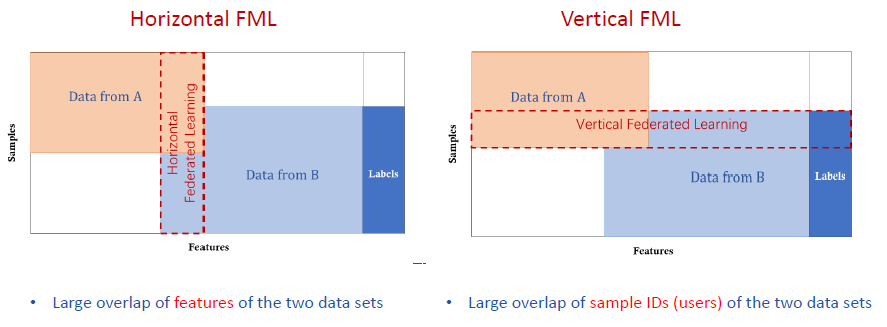
Horizontal Federated Learning
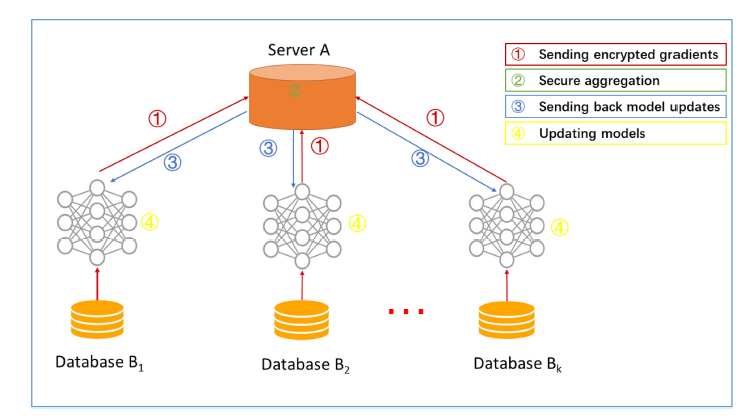
Horizontal Federated Learning applies to circumstances where we have a lot of overlap on features but only a few on instances. This refers to the Google Gboard use case and models can be ensembled directly from the edge models.
Vertical Federated Learning
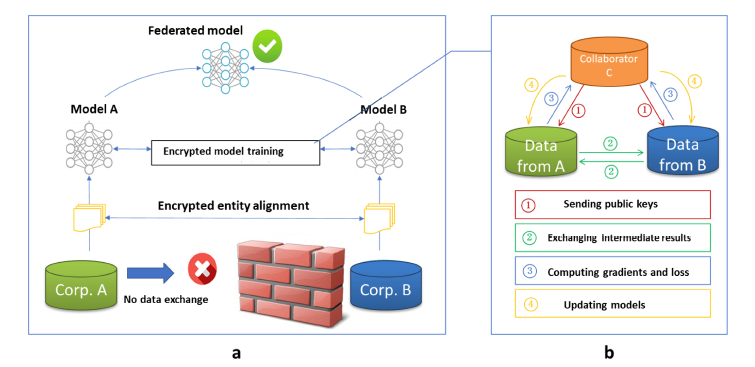
Vertical Federated Learning refers to where we have many overlapped instances but few overlapped features. An example is between banks and online-retailers. They both have lots of same users, but each own their own features and label data. Vertical Federated Learning merges the features together to create more powerful feature space for machine learning tasks and uses homomorphic encryption to provide protection on data privacy.
Federated Transfer Learning
Federated Transfer Learning uses Transfer Learning to improve model performance when we have neither much overlap on features nor on instances.
For a detailed introduction of the categorization of federated learning and their respective technology that is used, please refer to [5]
Projects for Federated Learning
There are some prototypes developed for Federated Learning. We find two projects very interesting. One is the FATE(Federated AI Technology Enabler) platform developed by Webank (Prof. YANG Qiang’s team). Another one is the Tensorflow Federated Learning project developed by Google.
FATE
“FATE (Federated AI Technology Enabler) is an open-source project initiated by Webank’s AI Department to provide a secure computing framework to support the federated AI ecosystem. It implements secure computation protocols based on homomorphic encryption and multi-party computation (MPC). It supports federated learning architectures and secure computation of various machine learning algorithms, including logistic regression, tree-based algorithms, deep learning and transfer learning.”
The official FATE platform is at https://www.fedai.org/ with a nice workshop tutorial slide deck they presented in AAAI2019. The open source code is at https://github.com/WeBankFinTech/FATE. The project claims to support horizontal FL, vertical FL and federated transfer learning with a focus on secure protocols. This project is currently actively being developed, and according to Webank they plan to donate the project to Linux Foundation to encourage more open-source collaboration.
Tensorflow FL
“TensorFlow Federated (TFF) is an open-source framework for machine learning and other computations on decentralized data. TFF has been developed to facilitate open research and experimentation with Federated Learning (FL), an approach to machine learning where a shared global model is trained across many participating clients that keep their training data locally. For example, FL has been used to train prediction models for mobile keyboards without uploading sensitive typing data to servers.”
Tensorflow FL is the result from the Gboard use-case at Google we mentioned before. This project focuses on Horizontal Federated Learning with a large population of client devices with heterogeneous computing capabilities. As with Tensorflow the project is open-sourced at https://github.com/tensorflow/federated.
Federated Learning Applications
Federated Learning is expected to be used in a lot of different applications. Here we list some as examples:
AI on Mobile Devices
With the Gboard case for Google as a first example, we expect Federated Learning to be widely used for AI on mobile devices including intelligent image processing for cameras, better voice recognition and NLU for virtual assistants, improved recommendation system for advertisements etc. Most of the existing pipelines of collecting mobile data into a centralized server for analysis can be developed with Federated Learning.
Healthcare
Health data is extremely private for patients, and people are looking into using federated learning to train machine learning/deep learning models for healthcare applications while protecting the privacy of patients.
“A handful of companies, including IBM Research, are now working on using federated learning to advance real-world AI applications for health care. Owkin, a Paris-based startup backed by Google Ventures, is also using it to predict patients’ resistance to different treatments and drugs, as well as their survival rates with certain diseases. [6]”
Finance
Federated learning can be expected to also apply to a wide range of financial use cases. For example, for anti-fraud across different banks, for risk modeling and pricing with banks and insurance companies collaborating with 3rd parties like internet companies that have a lot more customer data.
Specifically, for reinsurers, we can build an insurance federation with different primary insurers and 3rd party companies to together build machine learning models for insurance industry:
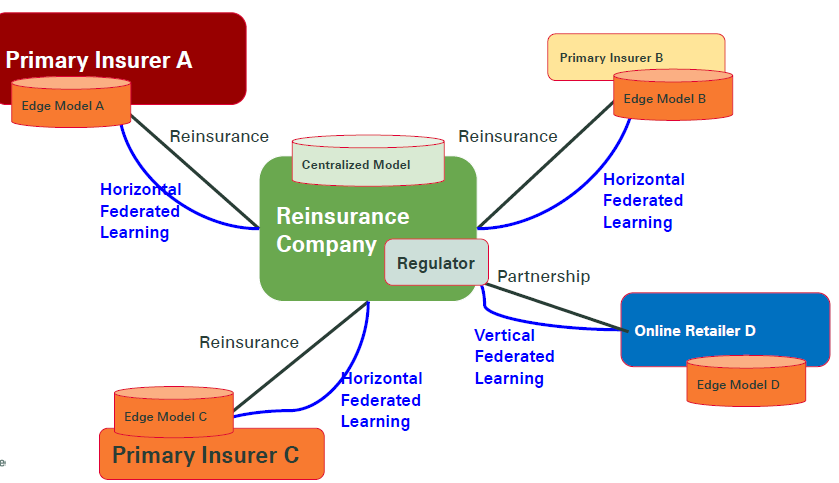
Outlook
From a practical point of view, there is still a gap between the current federated learning technology and real industry usage. We list some of our thinking below that may help close this gap.
Federated Learning with Hierarchy Layers
There can be hierarchy layers for the federated learning structure. For example, for insurance federation, we will have end-customers, primary insurers and reinsurers in the different level of the federation. How to manage the models across the different layers is still an open question.
In the long run, we may also have p2p federated learning where end customers may connect with each other directly for training a model without disclosing each other’s data. Protocols behind such case can be even more challenging.
Heterogeneous Clients for Federated Learning
In real use cases, the data from each client can be quite different in feature space. Some clients may have one set overlapped features, while others may have another set of overlapped features. This will result in a hybrid version of vertical and horizontal federated learning or even the transfer learning method to make best use of all the data.
On the other hand, computing resource for each client is also heterogeneous. This problem has been partially handled in horizontal FL by Tensorflow FL.
Regulation/Audition Solution
Regulators and auditors will play a crucial role for federated learning applications. How they are involved into the federation is an open question. Regulators not only can be educated and assured on the technology, but also can play as one important party in the federated learning setup where they can directly tap into the system to audit and contribute.
Incentives/Credit Allocation
Different clients may have different amount and quality of data and different levels of computing resource, thus their contribution to the final model performance will also be very different. It is crucial to build a fair credit allocation system and incentive mechanism to encourage clients to continuously take part into the federated learning system and make it a win-win situation for everyone.
Federated Learning Management Platform
As a multi-party system, besides the robust and efficient algorithms, we also need a federated learning management platform to give a easy-to-use interface and tool for the clients, model-builders and auditors to check, monitor, configure and analyze the system. Such piece of engineering work is crucial for federated learning to become a real product.
Reference
[1] ”Federated Learning: Strategies for Improving Communication Efficiency”, https://pmpml.github.io/PMPML16/papers/PMPML16_paper_20.pdf
[2] ”Federated Learning: Collaborative Machine Learning without Centralized Training Data”, https://ai.googleblog.com/2017/04/federated-learning-collaborative.html
[3] ”能够保障安全隐私的大数据算法「联邦学习」到底是什么?”, https://www.chainnews.com/articles/769415855789.htm
[4] ”联邦学习”, 杨强、刘洋、陈天健、童咏昕, CCF, https://dl.ccf.org.cn/institude/institudeDetail?id=4150944238307328&from=groupmessage&isappinstalled=0
[5] Qiang Yang, Yang Liu, Tianjian Chen, and Yongxin Tong. 2019. Federated Machine Learning: Concept and Applications. ACM Trans. Intell. Syst. Technol. 10, 2, Article 12 (January 2019), 19 pages.
[6] https://www.technologyreview.com/s/613098/a-little-known-ai-method-can-train-on-your-health-data-without-threatening-your-privacy/