开源技术带来的行业搅局者
开源让技术更好更便宜
现如今如果你是一名开发者,开源是你绝对绕不开的部分。你的操作系统很可能是开源的Linux,数据库可能是mysql或者mongoDB,从hadoop、spark到pandas,从pycharm到jupyter,从sklearn到tensorflow、pytorch,开源软件已经渗透到开发的方方面面。而从ImageNet造就的一大批开源预训练图像模型到word2vec以至BERT生成的开源自然语言预训练模型也已经被很多实际的产品使用。某种程度来讲,当我们谈论AI如何改变世界,我们其实是在谈论开源是在如何改变世界。大部分最先进的工具和算法在发布学术论文的同时也被开源在github上,然后迅速被全世界的开发者不断改进和使用。
前几日回到办公室,收到德国寄来的包裹,里面有T恤、胸针、贴纸和一张Rasa寄来的感谢信。两年前开始给Rasa贡献代码,拓展了自然语言理解部分对中文的支持;两年后Rasa已经是最受欢迎的开源chatbot框架之一,而官方文档关于中文语言的部分依然指向了我的博客。

Lemonade是一家美国的创新型保险公司,大量使用chatbot、AI技术和行为经济学革新保险客户的体验,而Rasa是他们chatbot背后的技术。如我一样的开发者虽然供职于其他公司,贡献代码给Rasa,变相也是帮助了Lemonade。类似的例子很多,Google主导开发了Tensorflow,身后也有一帮自己的开发者在使用Facebook的PyTorch,反之亦然。开源创造了良性的社会共赢,也大大降低了算法的门槛。
中国公司曾经一度被人诟病是模仿和抄袭者,而如百度、阿里巴巴和腾讯如今也成为开源世界的中坚力量。一方面开源自己的技术可以拓展生态宣传产品,可以引来大批开发者一起改进工具,另一方面对一些核心开源项目的贡献也成为了衡量企业在相关领域水平的试金石。不只是互联网技术公司,很多传统企业在转型中也开始有了自己的开源政策。
因为开源,一个初学者也可以在短时间内使用到最先进的技术。技术的门槛已经越来越低乃至到无门槛,于是就涌现一帮行业搅局者。这些“搅局者”有一些靠信息不对称收割些投资者、用户和雇主的智商税,也有一批踏踏实实做出了令人惊叹的成绩,真正搅乱了行业的格局。



但是数据不便宜
技术免费的时代就是数据为王的时代。有海量数据的公司就是年年亏损也依然能傲气十足被投资者们追捧,因为数据为他们创造了无所比拟的竞争壁垒。政府机构同样深知数据就是生产力,积极推进公众相关的数据公开项目,如香港政府的open data和香港保险业监管局与Shift合作建立的保险索赔欺诈识别数据库。
海量数据之中,能被机器学习模型直接有效用到的不见得多,这些才是数据中真正有价值的部分。数据工程师们大体都有类似的体验,一个项目中一半或以上的时间不是在建模而都是在清理数据;这还是有可用数据的情况下,若运气不好没有数据或数据质量不够,可能还需要大量时间爬取相关数据和人工标注样本。一个聪明又好看的数据标注工具非常重要。
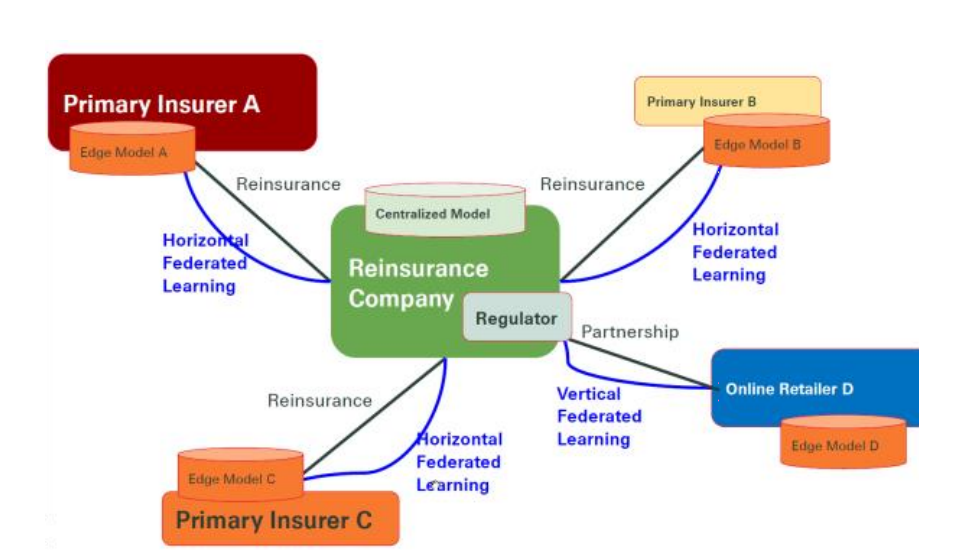
另一些情况下,不同方持有不同的数据,各自因为商业或其它原因无法分享数据,造成了大量的数据孤岛,无法彼此协作发挥数据的作用。不同保险公司因为竞争关系没有动力分享数据;保险公司自己也只拥有保单持有者有限的特征数据,如银行、互联网公司等拥有大量用户行为特征数据的公司又因为数据隐私问题无法和保险公司分享。我们正在探索如联邦学习这样的技术,希望能够在保证数据隐私和多方各自数据所有权的前提下打破数据孤岛之间的壁垒,建立行业的数据生态。
计算资源不便宜
随着技术的发展,越来越多的新技术尤其是深度学习对计算资源提出了极高的要求。前几年我们还可以自己去拼几块GPU卡跑跑模型,但如今上则百万参数的图像深度学习模型和自然语言处理BERT系列的模型都已经远远超过普通民用计算资源的标准。一边感慨技术民主化的渐行渐远,一边也得乖乖套腰包寻求更贵的计算资源。
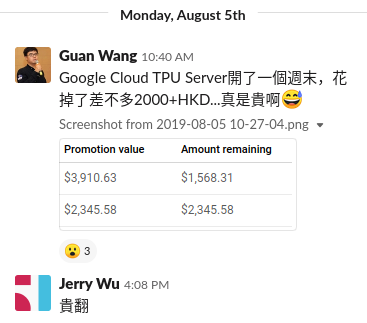
计算资源这一块,亚马逊、谷歌、阿里、腾讯这些大企业早早就布局好了。谷歌定期会给认证的开发者赠送谷歌云平台免费额度。之前为了跑BERT不小心开了一个周末的空闲TPU服务器,竟花去了两千多港币,连谷歌自己人都和我一起咋舌…
产品不便宜
出名靠开源,赚钱靠前端。这也是大部分初创公司应该专注的方向:炫技式的开源赚够了吆喝,但包装成产品真要真金白银卖得出去,还是要靠一点一滴的产品化以及大量体力活的前端设计和开发。
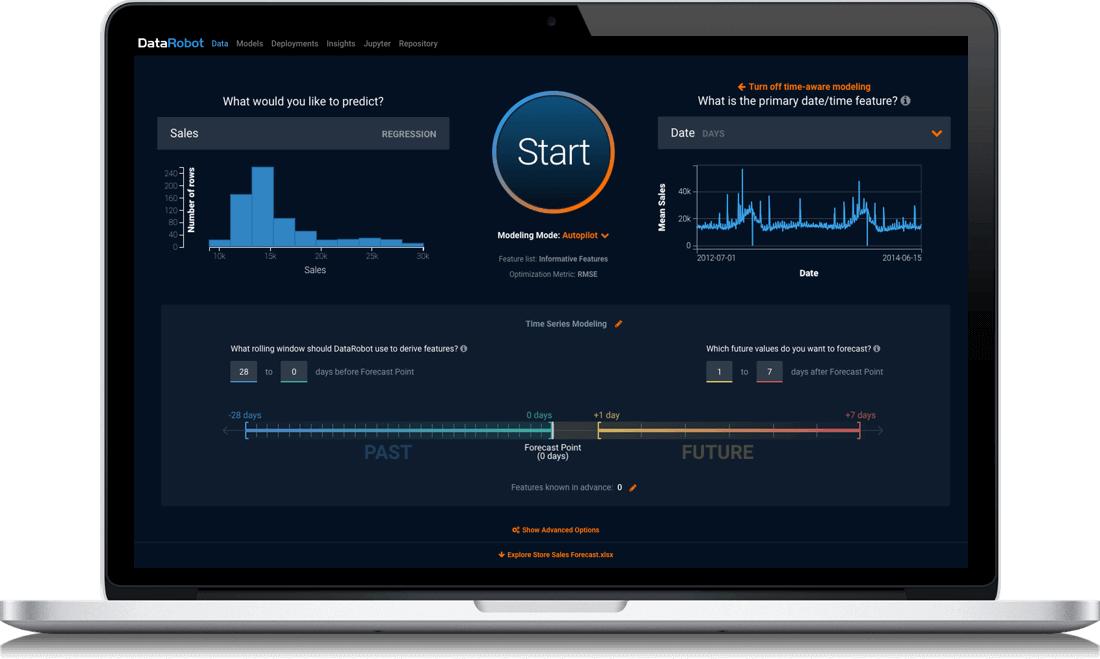
DataRobot是一个自动化机器学习建模的产品,用户只要定义好数据和预测标签,DataRobot就能尽可能自动化做好特征提取以及几十种不同算法的建模比较,给出模型预测结果甚至模型的可解释性。开源的AutoML技术现在已经不新奇,但我以为DataRobot的优势就在于傻瓜化的用户交互:数据拖进去,选好预测目标,点个run就够了。类似的例子还有Rasa X的傻瓜化建立chatbot的流程和Prodigy by SpaCy的傻瓜化标注数据的前端。漂亮的UI和傻瓜化的流程是抓住用户的杀手锏。
领域知识不便宜
常常有公司的精算师和核保师同事半开玩笑地问我,有你们在,我们是不是快要没工作了。其实技术不是偷去了你们的工作,技术是变革了你们的工作。
前面提到的标注数据是训练有监督机器学习的重要部分。而在如保险这样的垂直行业,没有领域知识的人是无法做出正确的标注的。机器给出的结果更是要时常被有专业知识的人审计之后才能保证其有效性和公平性。AI其实不只是Artificial Intelligence,更是Augmented Intelligence,是用来使精算师和核保师们的工作更高效。
其实公司里最有危机感的就是精算师们,他们也在疯狂般学习着数据科学。精算师们所在的专业团体也经常组织数据科学相关的培训。之前给澳洲的同事们开数据科学的workshop,最积极的就是精算师们,这里厚颜无耻地放出他们的反馈:

我们也(暂时还)不便宜
要把以上所有这些串起来,还是需要人、从、众。数据科学还未有如精算师一般严格的教育体系,无论是常春藤博士还是Coursera证书的光荣持有者都没关系,能找出问题、解决问题、创造价值的猫就是好猫。据我所知我们团队和很多其他公司的相关数据组都是常年招不满人。这些数据开发者们,到现在为止还都是挺贵的。