那些年我们一起写过的爬虫
在一家能从业务里源源不断产生数据的公司工作是一件很幸福的事情,但很多人如我就没有这样幸运。没有数据又想蹭住人工智能的风口,一种方法是潜心学术研究算法,但用来做实验的数据往往都是学术界或者一些好心的工业界提供的低配版数据,练就的屠龙刀倚天剑离实战还有很多距离;另一种方法就是费尽心机寻找真实数据。在聊(已经学不动的)各种神乎其技的算法之余,我也想简单总结下那些年我们写爬虫的经验。
甄选网站
写爬虫之前先要从需求出发寻找合适的目标网站和数据源。
首先,能有API调用或者能从别的渠道买到的数据就尽量别再自己写爬虫了。除非目标网站的数据非常容易爬,否则写爬虫是一个非常繁琐且需要长期斗争的体力活。从各个IT大厂的云服务,到一些爬虫起家的数据公司,甚至在某宝上面,都有大量的API或者数据的服务。首选API的服务因为一般数据提供商会按照API调用次数收费,配合API的query条件可以比较好满足自己的特定需求,数据提供商一般也会保持数据更新;如果是直接买数据一开始报价中就要谈好更新数据的后续报价。
几个数据源的例子,比如百度数据开放平台:
香港政府的资料一线通(更新很快,最新的冠状病毒数据也已经传在上面并且保持更新):
如果真的要自己写爬虫,那就要开始调研目标数据所在的网站。一般都会有多个网站提供目标数据,我们要挑看上去数据简单排列整齐的(一个表格很多下一页那种),排版看上去土土的(网页代码简单好写parser),没有太多控件,最好也不用账户登录更不要没事跳出一个验证码的那就是坠好的。越冷门的网站一般也越好,因为可能访问量不高,网站管理者也不会设置太多的爬虫限制。
业务方常常会提出比如去几千个不同网站上去分别爬取信息的需求。这是不现实的,因为我们并不是谷歌或者百度这样的搜索引擎,不同网站结构不一样,意味着我们可能要分别写几千个爬虫才能爬取所有的信息,更不要提之后的维护工作。最佳的情况是目标数据存在同一个网站内,网页结构单一可以直接一次性爬取,后续维护工作也比较简单。有时候我们也会爬两到三个不同的网站然后做数据的cross validation,因为有的网站数据不见得是完整正确的,甚至一些网站检测到爬虫还会主动给你feed假数据…
爬虫框架
市面上有多种不同的爬虫框架可以选择,不同的框架也可能基于java或者python等的不同语言。如scrapy这样的爬虫包已经将很多爬虫功能如多线程并行爬取等打包实现。
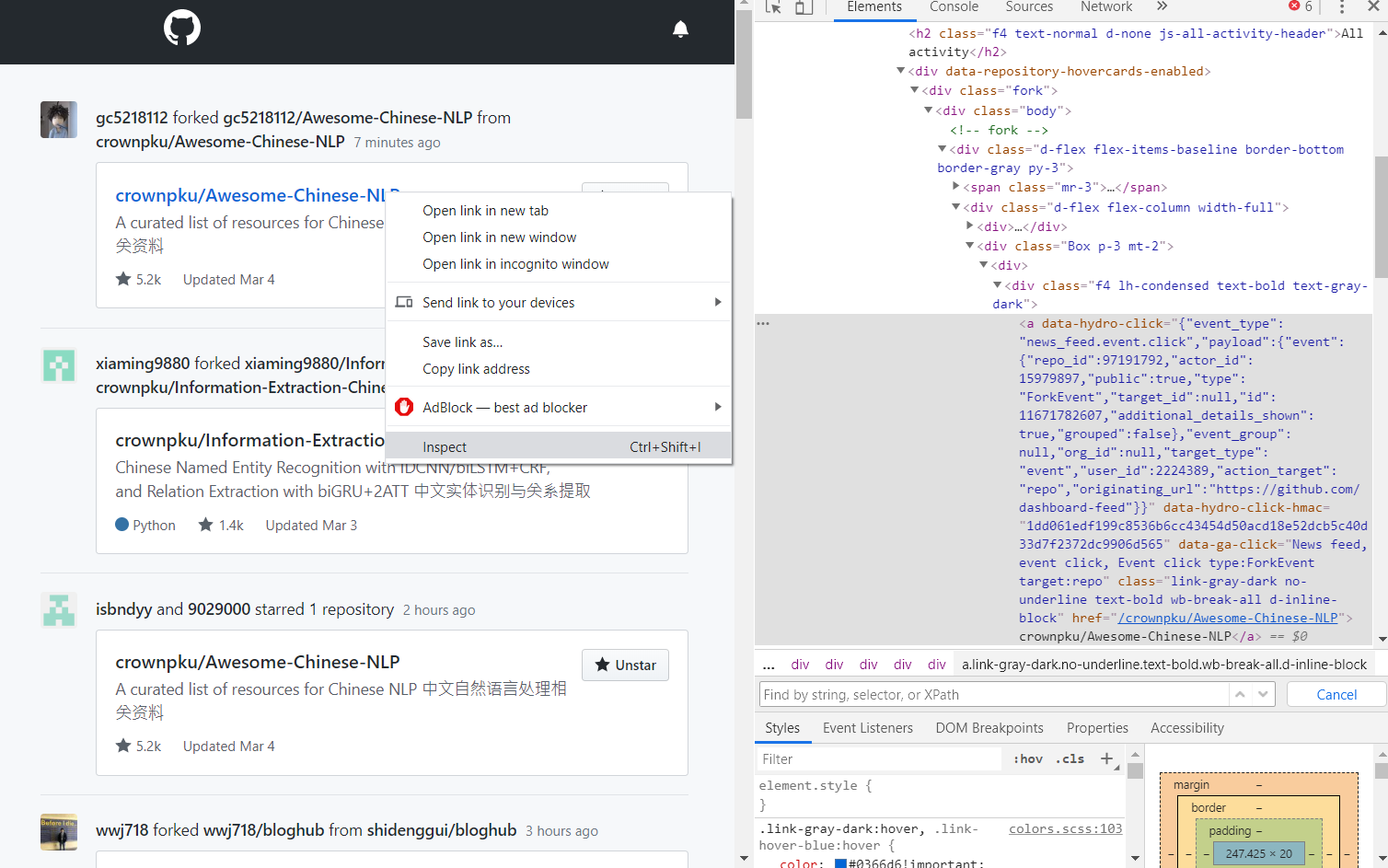
当年自己写爬虫主要是python栈,简单的流程就是使用selenium做框架,phantomJS做模拟浏览器拿到源代码,然后用xpath或者beautifulSoup做网页解析得到目标数据。解析前一般会用chrome的debug模式先直接在网页中测试xpath的解析逻辑是否靠谱:
相应的爬虫代码教程很多,这里不再啰嗦。
搏斗经验
写完爬虫代码,把代码跑起来,这才是一条爬虫和目标网站搏斗的刚刚开始…下面是冰山一角的几条经验:
-
断点续爬。这个很重要,因为你的网络很可能不稳定,中间爬虫很可能会断掉。如果每次断掉都重头开始爬数据可能永远也爬不完,所以一定也写好error handling也就是try exception的部分,connection error之类发生以后要及时等待重试而不是退出程序。
-
浏览器加header。这个也很重要,因为很多时候如果网站服务器发现你明显是一个headless的爬虫浏览器会即刻拒绝掉你的网络请求。一个典型的header如下:
{'Accept': '*/*', 'Accept-Language': 'en-US,en;q=0.8', 'Cache-Control': 'max-age=0', 'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/48.0.2564.116 Safari/537.36', 'Connection': 'keep-alive', 'Referer': 'http://www.baidu.com/' } -
模拟登录、随机等待时间等等,这些都是为了模拟真实用户的行为,防止激活网站的反爬虫机制封杀掉你。
-
如果不幸你的ip被网站封杀了,就需要使用ip代理继续爬取数据。实际上ip代理是爬虫中非常重要的一环。有了大量代理ip就可以放心做多线程爬取,一个ip封掉可以自动及时替换为另一个ip。网上有一些免费的ip代理服务,但是速度和稳定性都不够;一般推荐付费的ip代理服务如kuaidaili,会提供API直接调取和动态更新代理池,稳定度也会好很多。
-
爬虫维护。网站改版、网址改动、新数据上线等都可能造成原先的爬虫不再适用,加上目标网站的IT也会不断更新反爬虫策略,所以爬虫维护是一个持久战。
另一个障碍是很多网站为了防止爬虫还会设置有验证码。不过道高一尺魔高一丈,我曾经也和各种验证码搏斗过一些时间,而且这个经验很有意思,我下面单独聊聊。
干掉验证码
比较古旧的网站验证码往往是如下的样子:

这种验证码的破解方式其实就是训练一个OCR的模型去模拟人识别这些扭曲变形或者不同背景的文字。然后训练一个针对某一种验证码的OCR系统是需要大量训练数据训练一个图像识别模型的。莫非我们还要去大量爬取验证码图片先?实际中大部分情况的做法是,通过观察验证码的样式,写一些简单的规则自己生成类似的验证码。比如调整字体,随机做图片扭曲,加一些横竖的裂纹线,或者加上不同背景花纹和颜色等等。规则写好,就相当于有一套系统可以随机生成无限多的训练数据,这样就可以当作用如卷积网络这样的模型,最后面一层是26个英文字母的分类,训练出一个验证码识别的模型。
我们当年的实际情况是遇到了中文验证码,而且是中文或者成语,有时候还是数学公式:
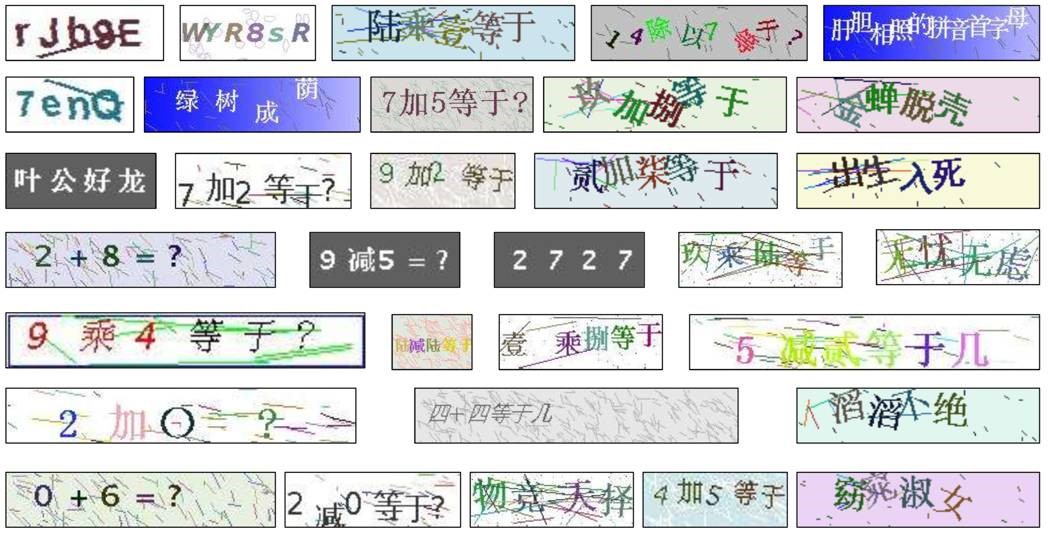
这就大大加大了模型验证的难度,因为汉字个数要远远大于英文字母的个数。不过对于成语来讲,我们又单独爬取了一个成语库。这样对于识别出来的四字中文如果有一两个识别错了,我们会计算相似度从成语库中找到最相近的正确成语,这样就大大提高了识别的准确度。
当我们的深度学习验证码识别系统完美工作,爬取了数天数据之后,我们发现网站忽然改版了。新的验证码变成了这样:
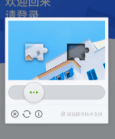
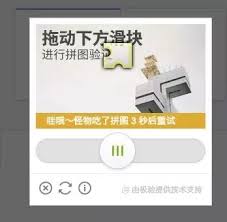
要找到拼图,然后拖动滑块到拼图的附近才可以成功。
于是我们再次用图像处理的方法找到拼图,却发现如果只是直接模拟把滑块拖过去依然会验证失败。我们找到了这家验证码服务的提供商,然后发现他们的文档里说他们也使用了人工智能技术来通过拖动滑块的鼠标轨迹和速度以及拼图契合度来判断是真人还是机器人…如果匀速直线拖过去然后完美契合拼图也会悲剧。
于是我又用了将近一个月的时间研究如何模拟出完美的鼠标轨迹来骗过验证码。当年的成果现在还在github里面躺着,有兴趣的读者可以去挖一下坟。那时候已经崩溃到考虑用强化学习Reinforcement Learning来做破解了…
现今的验证码已经基本到了神乎其技的阶段了。以Google为例,居然在用验证码帮助收集图像识别的标注数据,也是真的醉了…
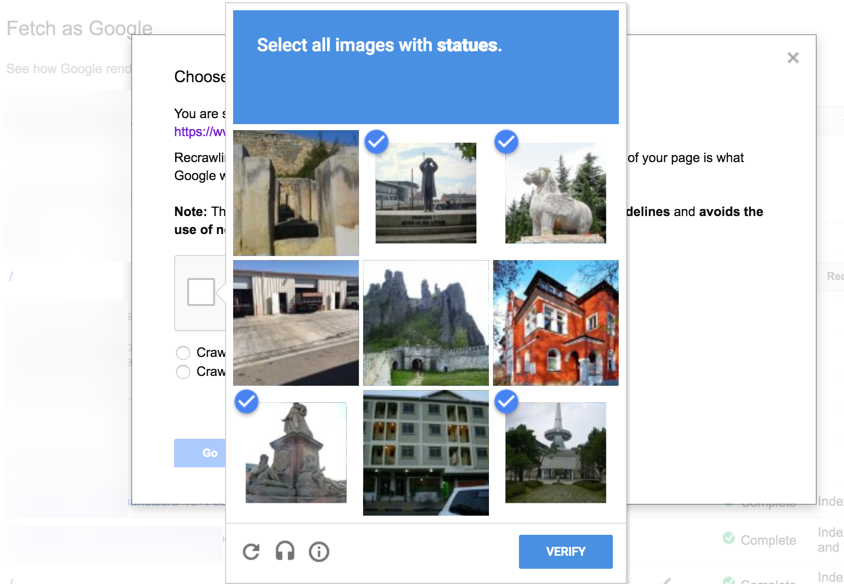
总结
业务有数据最幸福请珍惜。没数据想要爬数据,先做调研看看技术难度,情况不妙就找数据提供商,不要怕花钱因为自己开发和维护爬虫的开销很可能更大。真要自己硬杠开发爬虫的话,请对时间、资金和脑力的投入做好充分的心理准备,可能开发过程把你逼成一个深度强化学习的AI大神也不一定…
爬虫是一门可以非常艰深的任务,某种程度上也其实是如谷歌和百度这样的搜索引擎的根基,网上也有很多的爬虫工程大神。这篇文章只是分享自己曾经写爬虫的的些许经验,希望能抛砖引玉(或是吓走一批想要学习爬虫的人…)