土味十足的spaCy官方中文免费网课
spaCy 终于终于支持中文模型了
spaCy 是自然语言处理界有名的工业级别开源工具。最新更新的2.3版本中,在@howl-anderson 等码友的贡献努力下,spaCy 终于官方支持中文模型了。
spaCy 同时推出了官方中文的免费互动网课:
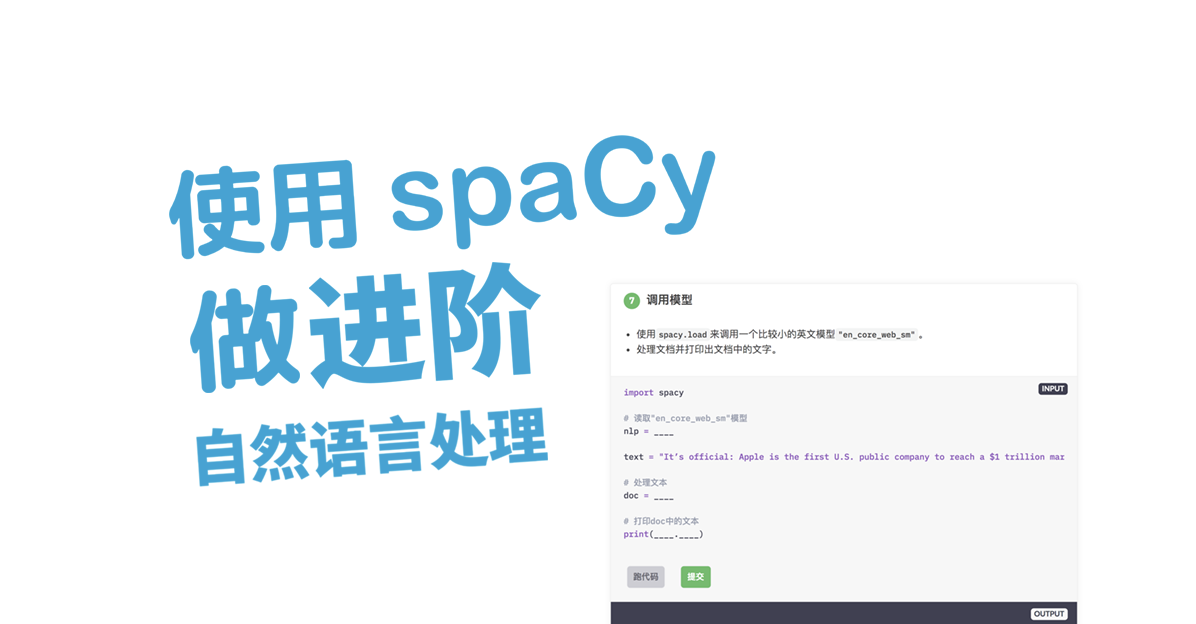
中文版课程针对中文 spaCy 模型特别定制,土味十足:
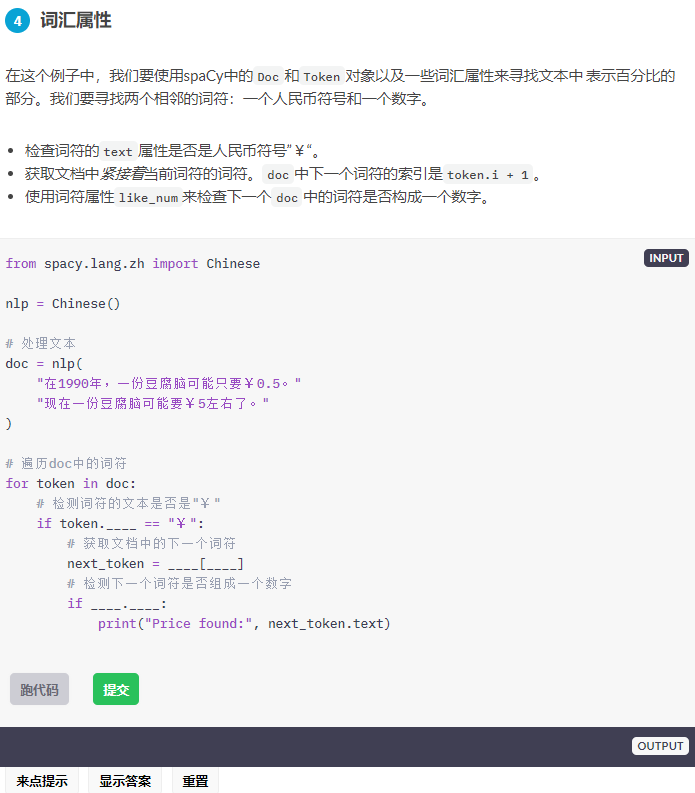
吃了吗您?
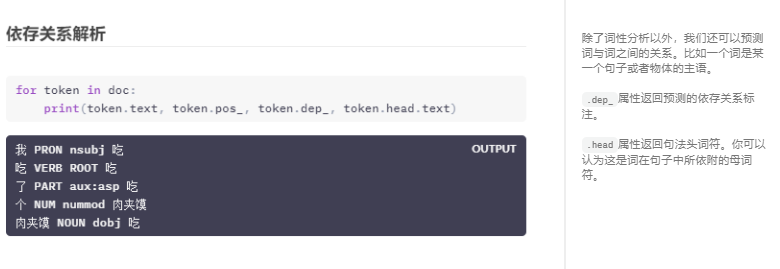
你会学习到的spaCy技能
- 抽取语言学特征:词性识别,依存关系,命名实体
- 学会使用预训练好的的统计模型
- 用
Matcher和PhraseMatcher来匹配规则寻找目标词汇和短语 - 使用数据结构
Doc、Token、Span、Vocab和Lexeme的最佳实践 - 使用词向量来计算语义相似度
- 编写定制化的流程组件来生成扩展属性
- 规模化你的 spaCy 流程使其运行速度更快
- 为 spaCy 的统计模型创建训练数据
- 用新数据训练和更新 spaCy 的神经网络模型
spaCy 官方免费中文网课包含有四章内容,分别如下:
第一章中我们学习如何抽取语言学特征,比如词性标注的标签、依存句法关系和命名实体等, 以及如何使用预训练好的统计模型。
我们还会学习书写一些非常强大的匹配模板来用spaCy的匹配器 Matcher 和 PhraseMatcher
抽取目标词汇和短语。
第二章是关于信息提取,我们学习如何使用数据结构 Doc、Token 和 Span,以及 Vocab
和词条 (lexical entries)。
我们还会用 spaCy 读取词向量来计算语义相似度。
第三章中我们深入研究 spaCy 的流程,学习如何书写我们自己定制化的流程组件来更改输入的 doc。
我们为 doc、token和 span 创建了我们自己的定制化扩展属性,还会学习流处理的方法来让我们 的流程跑得更快。
最后,在第四章中我们学习如何训练和更新 spaCy 的统计模型,特别是命名实体识别器。
我们会学习到不少有用的技巧来创建训练数据,以及如何设计我们的标注内容来得到最好的结果。
面对疾风吧
土味十足的spaCy官方中文免费网课👉 course.spacy.io/zh
更多示例、教程和详细的API文档👉 spacy.io