机器学习模型的公平性评测
在这个黑人牙膏要改名、护肤品也不敢标称自己美白效果的年代,机器学习也不能幸免于接受社会对其政治正确的审视。一个计算机视觉的去马赛克算法不慎将奥巴马转化成了一个白人面孔,引来网络上一片骂战,大神Yann Lecun都被骂退推特。
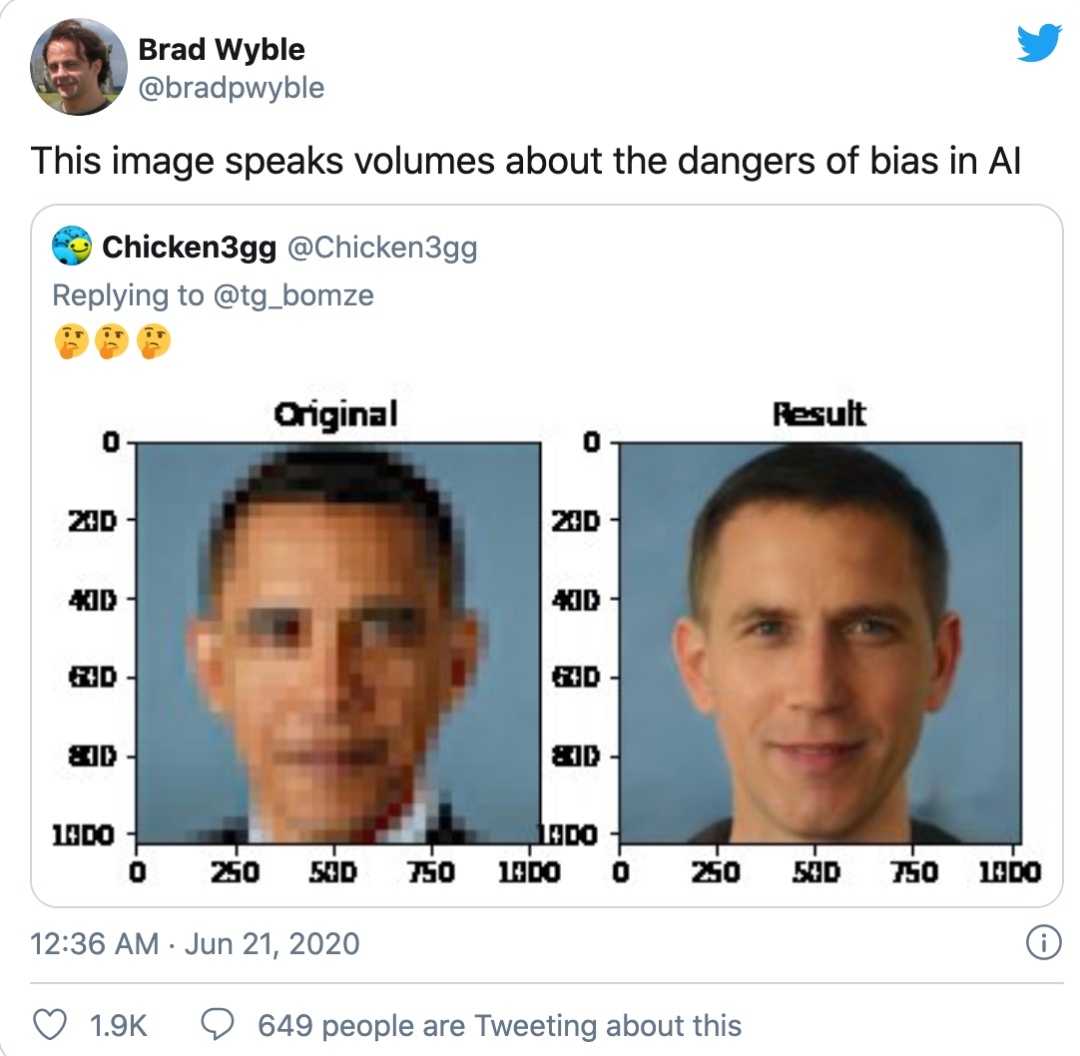
这个世界本身就充满了偏见和歧视,而基于真实数据构建的机器学习也不免引入了这样的不公平性。构建一个不公平的机器学习模型并不可怕,关键是如何评测和优化模型的公平性,使其尽可能引入人类对正义的理解,摒弃数据中的偏见与歧视。
我们从评测和优化两个角度,以技术的眼光聊一聊机器学习模型的公平性。这篇博客先关注机器学习公平性的评测,后面我们有机会将再探索公平性的优化。同时插播一条广告:博主本着对自己负责的态度计划记录更多的原创文章回馈社群,尽力做到周更,感兴趣的朋友们请长按二维码关注 微信公众号“王尔古” (ID: erguwang) 或 博客“羊肉泡馍与糖蒜” (www.crownpku.com) 。谢谢。

公平性缺失带来的伤害
公平性的丧失会带来很多负面影响,我们选择其中两个比较重要的,分别是“分配伤害”和“服务质量伤害”:
分配伤害 (Allocation harms)
分配伤害指AI系统在机会、资源或者信息上面过分照顾或过分忽略了某些特定群体。一些例子如招聘、入学、贷款等。
服务质量伤害 (Quality-of-service)
服务质量伤害指AI系统在某些特定群体上面效果很差。一些例子如人脸识别、文本搜索或者推荐系统等的准确度。
要定义上文中提到的特定群体,我们首先要定义一些”敏感特征”,如性别、年龄、种族等。这些特征类别勾画出的子群体是我们要特别关注的。但这并不代表这些”敏感特征“不能用来做模型训练和预测,实际上大部分情况下他们依然是模型重要的特征组成部分。后面会看到我们优化公平性的策略并不是摒弃敏感特征,而是去调节敏感特征上的数据分布。
公平性约束
敏感特征将群体分为不同的子群体,如男生和女生群体,或者不同的人种群体。我们在这里定义一些不同的公平性的约束方法,试图使用这些约束来规范模型的公平性。
特征无关 (feature blind)
特征无关要求模型的预测对于敏感特征所定义的每一个子群体都有一样的决策阈值。例如假如省份是敏感特征,高考录取是目标,我们要求高考录取分数对全国各省要求一致。这看上去这是公平的,但很有可能招进清华北大的大部分都是山东学生而没有诸如西藏和海南考生 – 这是否公平呢?
统计公平 (statistical parity)
统计公平要求模型的预测结果对于敏感特征是统计独立的。比如高考时我们的要求清华北大录入各省的考生人数比例与各省人口比例一致。这看上去是公平的,但很可能忽略了各省不同的教育资源程度 – 这是否公平呢?
平等机会 (equal opportunity)
平等机会要求模型仅针对有正标签的群体预测结果对于敏感特征是统计独立的。比如性别是敏感特征,银行放贷是目标,要求针对一直按时还贷不欠款的人群给出贷款offer的男女比例一致,而对于之前有拖欠过贷款的人则不做分布要求。
均等赔率 (equalized odds)
均等赔率比平等机会更严苛,要求模型分别对于正负标签的群体预测结果对于敏感特征是统计独立的。依然用银行放贷的例子,不但要求对信贷记录良好人群的贷款offer男女一致,对于信贷记录不良好人群的贷款offer结果也需要男女一致。
上述几种公平性约束中,特征一致和统计公平试图解决分配伤害的问题,而平等机会与均等赔率则试图同时解决分配伤害与服务质量伤害的问题。
公平性评测
评测一个已有模型的公平度,需要以上面提到的公平性约束为基准,检测一个模型与其相差多远。
以统计公平为例,我们定义 X 是特征向量,A 是一个敏感特征,h 是分类模型,则我们有:
-
统计公平差
-
统计公平比
实践
微软开源了其模型公平性评测的工具 Fairlearn ,其中包含了一些简单的API可以方便计算针对不同子群体的公平程度。
最难能可贵的是 Fairlearn 包含一个可以嵌入在 Jupyter Notebook 中的产品级别的仪表盘 ,可以让我们很方便可视化模型在不同敏感特征和子群体下的评测结果,以及不同模型的对比结果。该仪表盘也被微软整合在了其 Azure 云服务中。
注意,如果读者是将 Fairlearn 跑在 Jupyter Lab 中的话,会有仪表盘无法显示的可能性,此时需要选择菜单中的 Help -> Open Classic Jupyter notebook, 然后在经典的 Jupyter Notebook 环境下就可以运行代码跑出仪表盘了。
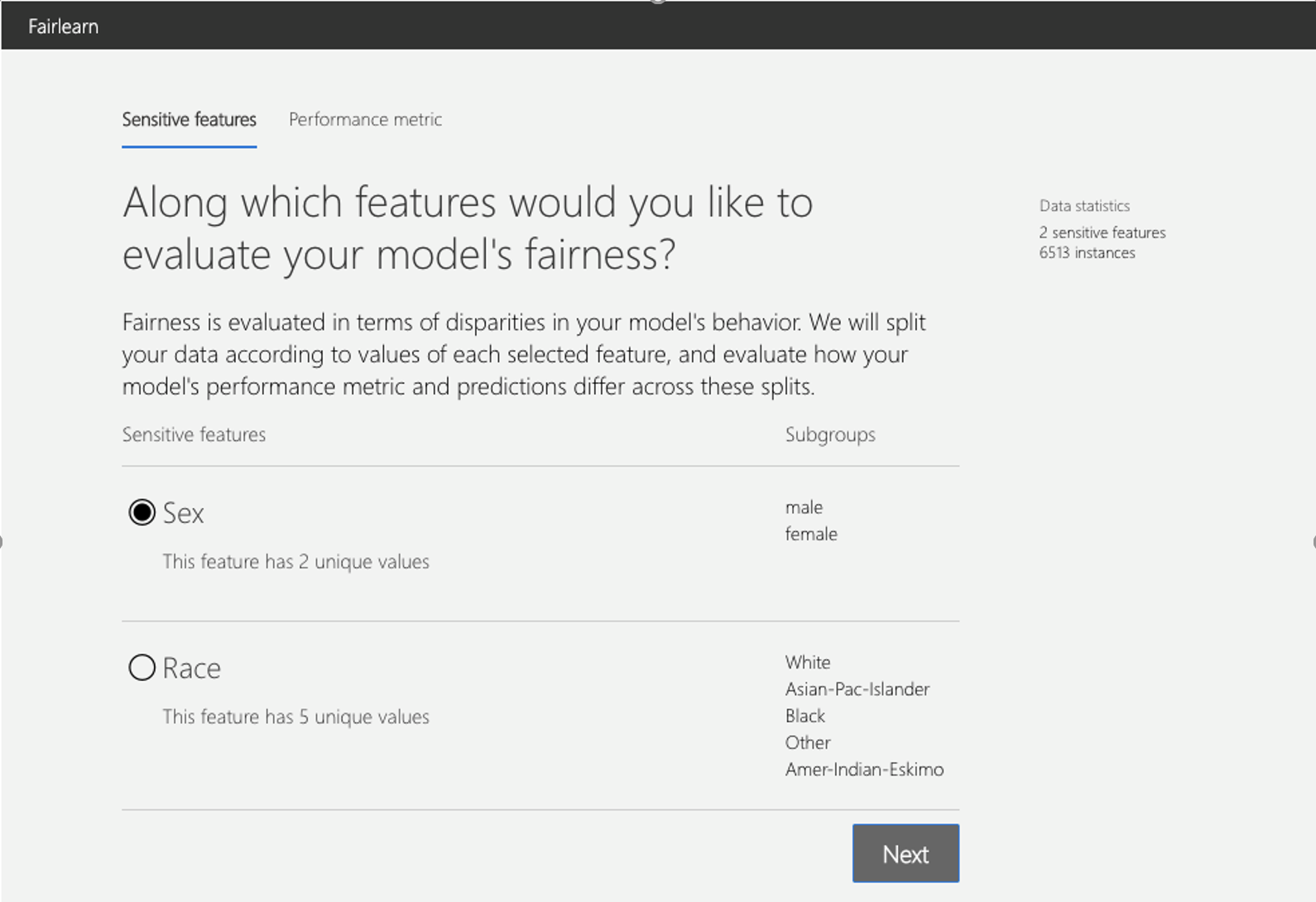
启动仪表盘后,首先需要选择敏感特征,如性别、种族等:
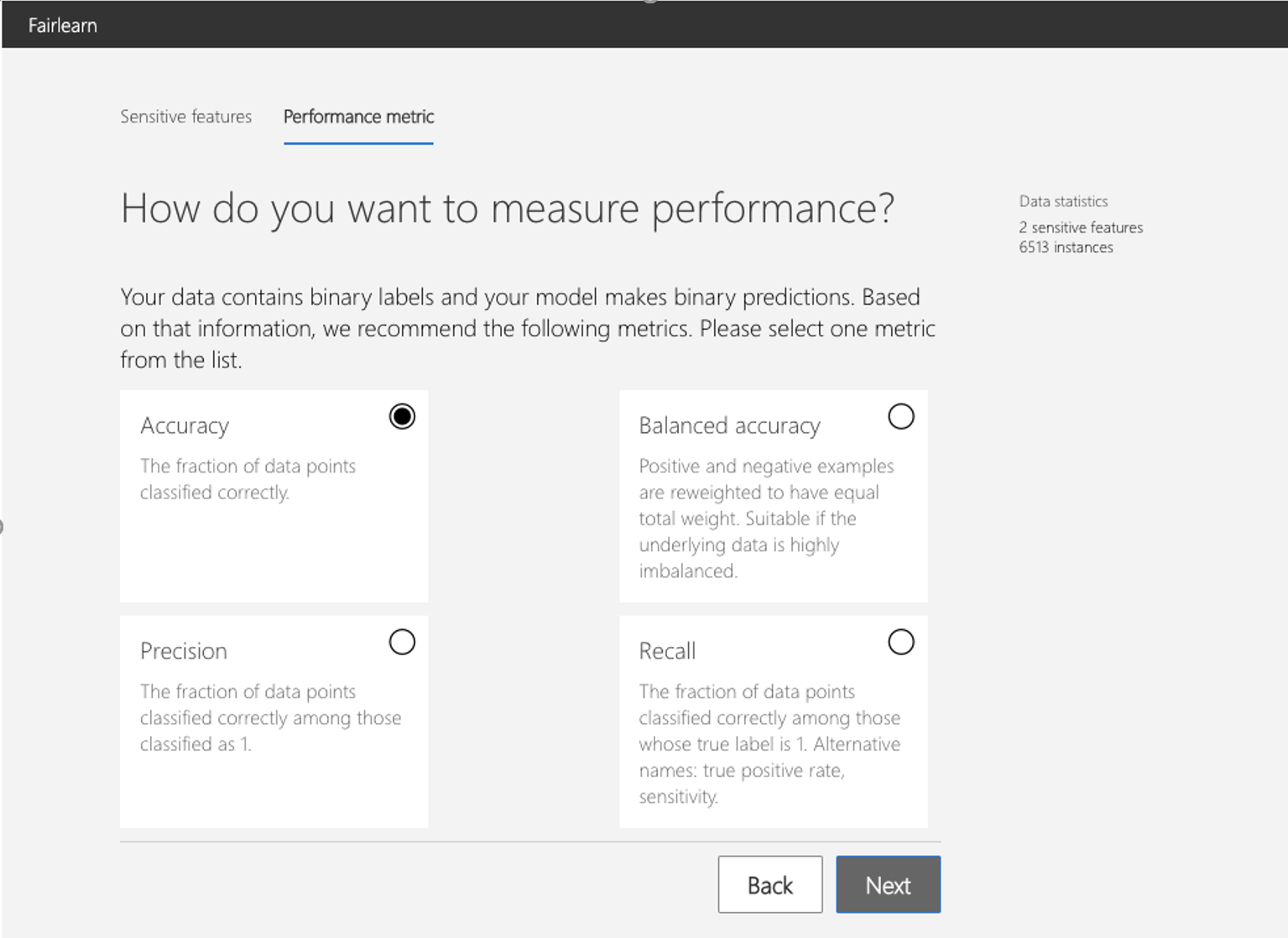
然后需要选择模型评测标准,如模型的准确度、精确度、召回率等,这个标准将会用来评价模型在全部群体以及不同子群体上面的表现:
设置完成之后,仪表盘会在两个界面中分别进行模型评测:
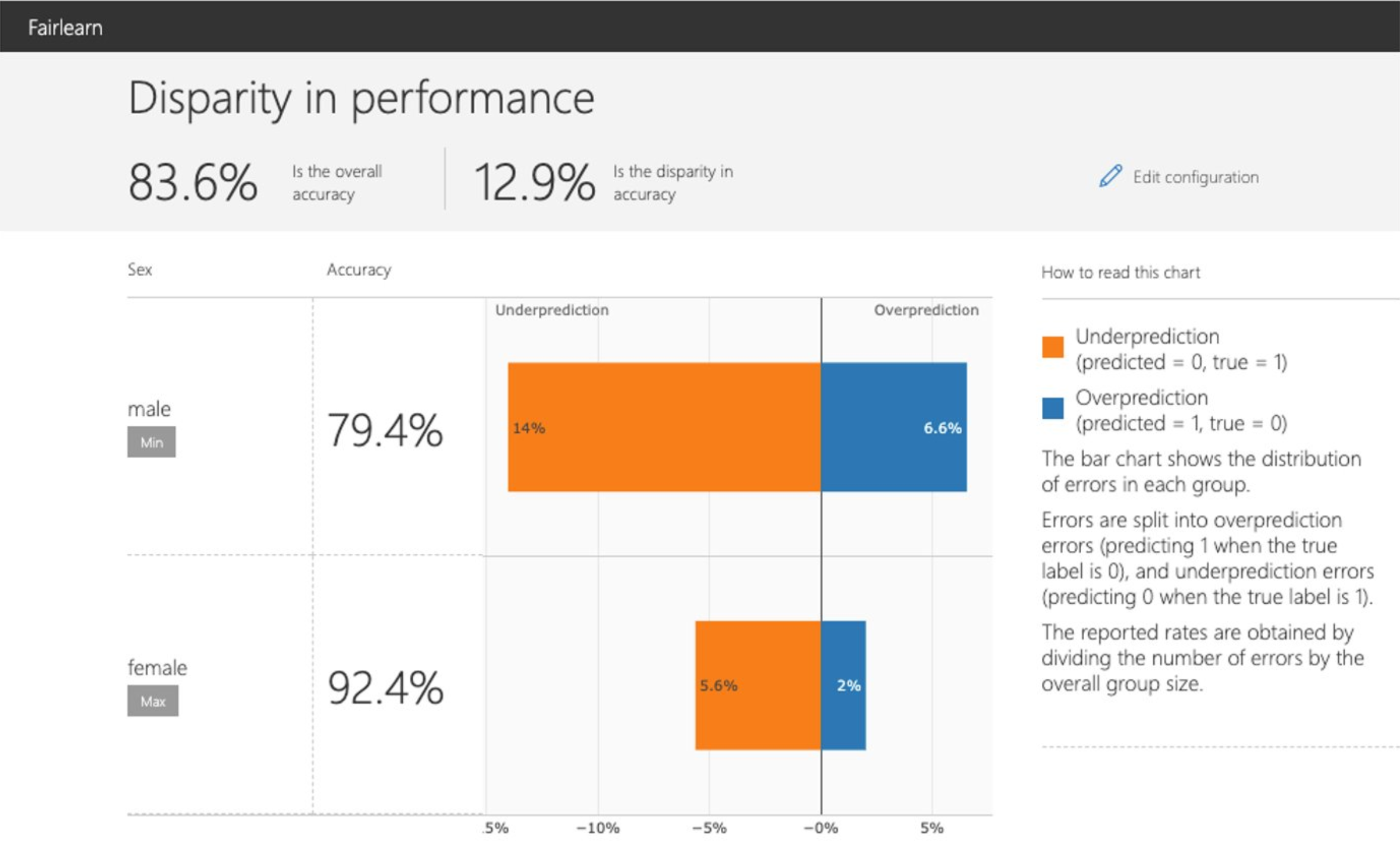
模型表现的公平性
-
模型评测标准(如准确度)在全体群体及不同子群体上面的表现(比如男性群体和女性群体的模型准确度)
-
在不同子群体上模型的统计公平差
-
在不同子群体上模型的错误分布(在二分类问题中,分为 overprediction 也就是把负标签预测为正标签以及 underprediction 也就是把正标签预测为负标签)
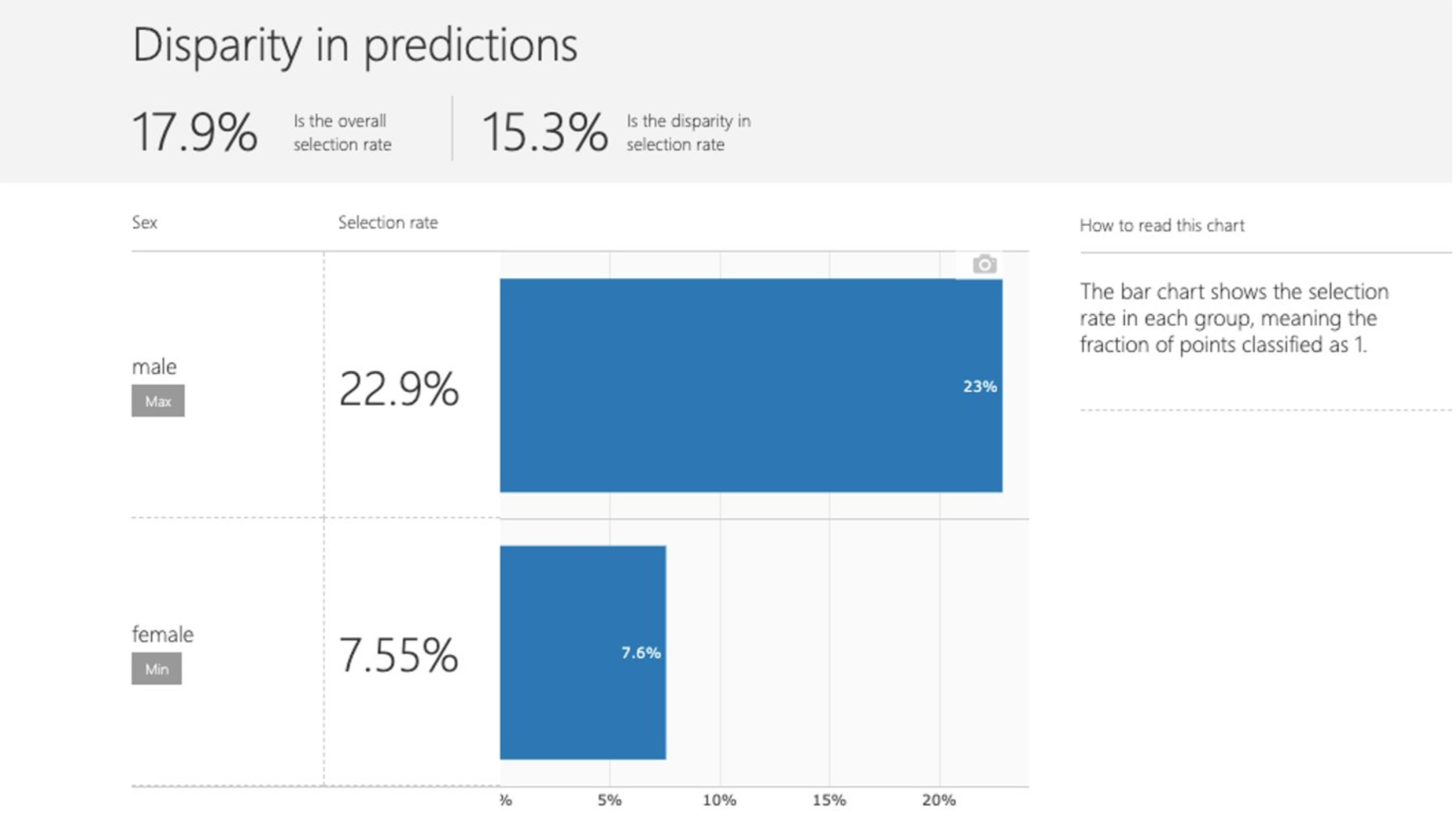
模型预测的公平性
-
分类问题中不同子群体的选择率,即预测正标签的比率
-
回归问题中不同子群体的选择率,即预测结果的分布
Fairlearn的更多功能,请移步其Github仓库:https://github.com/fairlearn/fairlearn
Reference
[1] https://fairlearn.github.io/
[2] https://fairmlbook.org/
[3] https://blog.acolyer.org/2018/05/07/equality-of-opportunity-in-supervised-learning/