基于示例解释机器学习
机器学习可以基于历史数据自动学习决策模式,而其中很多模式是人类经验和手写规则无法覆盖到的。这让机器学习成为从数据中获取更多价值的强大工具。
高性能模型始于高质量数据,但在许多情况下,数据集存在标签不正确或示例不清晰等问题,这些问题会导致模型性能不佳。我们常说Garbage in garbage out;复杂的模型结构、强大的模型算法、神奇的预训练参数,都抵不过实践中烂数据拖的后腿。
机器学习解释性
很多时候我们寄希望于机器学习的解释性来告诉我们模型究竟出了什么问题。常见的方法:
-
对于结构型表格数据的模型,例如GBT,通过诸如SHAP的方法计算特征重要性
-
对于非结构性数据的模型,例如图像分类,高亮出对分类产生重要作用的像素点
-
对于非结构性数据的模型,例如文本分类,高亮出对分类产生重要作用的文本段
以上的方法将复杂的非线性和互相作用的特征空间,通过诸如SHAP博弈论的方法,映射到反应其对模型影响力的线性空间上面。这大大帮助我们了解模型决策背后的逻辑。
然而这些方法在实践中也有很多问题,比如:
-
类似准确度的不同模型结构,其特征重要性差别很大,导致很难解释和决定使用哪个模型
-
完全相同的模型结构通过调参和再训练,可以产生很不同的特征重要性,其稳定性会让业务方质疑模型本身
-
线性映射的特征重要性无法完全展现特征在非线性和相互作用情况下的真实影响力,往往导致业务方宁愿牺牲模型准确度也要倾向于更好解释的诸如逻辑回归这样的简单模型。
模型表现不佳的原因
模型表现不佳,业务方觉得辛辛苦苦导出了大量数据,数据团队却达不到KPI,大家都很不开心,怎么办?
模型表现不佳,很有可能不是模型训练本身的锅。其它可能原因有:
-
要解决的问题本身定义不合适,业务目标与数据本身和模型优化目标不匹配(常见是KPI定义过高,与实际数据和业务情况不符
-
数据标签质量不高,很多错误标签
-
数据特征的预测性不够,没有采集到王牌特征(往往不是特征工程就能搞定的)
-
数据特征本身噪音很多,常见的是在历史中出现业务流程的调整导致特征定义改变,或者业务流程规范性不够导致不同数据源对相同特征有不同的输入,结果就是模型无法学习到一致性的特征到标签的模式。
我们看到很多时候有可能是数据源本身的问题。

吴恩达说:“最好的食材往往只需要最朴素的加工。”
哦不,应该是“机器学习应以数据为中心…80%的数据+20%的模型=更好的机器学习…调优数据比调优模型更重要”。
基于示例的机器学习解释
如果我们觉察到问题可能出现在数据本身,那么如何向相关部门合适地展现出问题和可能的解决方案呢?
一种方法自然是EDA,即对数据本身画出很多比如分布、相关性、时间序列等的可视化图。这往往是有效的,但缺点也很明显:数据团队(在没有太多业务知识和头绪的情况下)花费大量时间生成针对大部分特征的(很多冗余的)可视化结果,然后业务团队(在没有太多数据背景知识的情况下)花费大量时间检查每一个结果然后给出评论。很多时候EDA的方法往往是脱离模型决策本身的。
我们在这里推荐的方法是基于示例的机器学习解释。具体步骤如下:
-
找到模型出错的数据点A,尤其是那些置信度很高但仍然分类错误的点(远离于模型分类边界)。值得一提的是对这些点本身及其背后的模型预测特征权重做研究已经是一个诊断模型错误的好方法。
-
对于这些数据点,寻找其最相似的且分类正确的一系列数据点B。此处重点是“相似”,也就是如何计算相似度。结构化/表格数据最简单的方法是使用模型整体预测的特征权重计算带权重的余弦距离。也有很多计算embedding的方法将数据映射到一个嵌入层;这种方法更常见于非结构化数据如图像和文本,但也可以应用于结构化/表格数据。
-
研究A与B之间的关系。我们可以直观直接比对数据,或是对模型针对A和B的单个数据点做预测的特征权重做比对。
我们给出下面两个例子[1]。
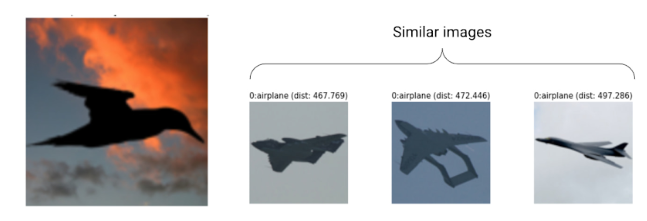
第一个例子是图像分类的任务。我们发现有一只鸟被分类错误。通过寻找与其最接近的20个样本,我们发现其中15个都是飞机的图像。这只鸟很容易被当作成为飞机。因此我们需要类似这种更多的黑色鸟影子的图像出现在标注数据中,让模型更好学习这些样本。这可以和主动学习active learning的流程衔接起来,让标注者特别针对这些易错的样本进行标注。
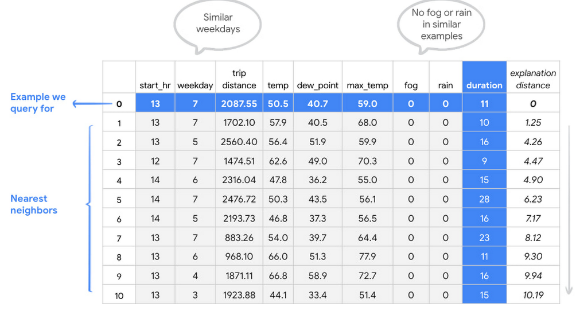
第二个例子是表格数据,通过不同特征来预测骑车的骑行时间。我们看到第五行的骑行时间duration对比其它类似数据来说格外长 – 可能骑手是推车走路,也可能是中间停下吃了点东西。无论如何这行数据以及比如第7行数据都比较可疑,因为在类似的情况下骑行时间一般不会这么长。这就需要我们仔细调查,然后决定是否将这些数据从训练数据中拿掉。
数据质量对企业来说是一个持续的挑战,甚至一些用作机器学习基准的数据集也存在标签错误,导致整个模型训练和评估过程产生偏差。机器学习模型通常难以debug。我们往往很难找到模型表现不佳的根本原因,也不知道解决问题的下一步是什么。基于示例的机器学习解释可以很好在这些方面帮助到我们。
Reference: [1] https://cloud.google.com/blog/products/ai-machine-learning/example-based-explanations-to-build-better-aiml-models