Taming the Giant:Fine-Tuning Gemma 4 E2B-IT into an Insurance Expert
In the world of AI, generalists are common, but specialists are rare. Today, I’m sharing the “black box” experience of fine-tuning Google’s latest Gemma 4 E2B-IT (5.1B parameters) to become a high-precision insurance advisor.
This wasn’t a standard “plug-and-play” exercise. We pushed the boundaries of Tunix (JAX) on a Google Cloud TPU v5litepod-4, encountered memory walls, patched library-level attention bugs, and learned some hard lessons about Per-Layer Embedding (PLE) tables. Here is the full, unvarnished technical journey.
1. The Architecture: Why Gemma 4 E2B-IT?
Gemma 4 is a fascinating specimen. While the “E2B” (Edge-to-Base) version is marketed as efficient, its internal architecture is surprisingly complex:
- Total Parameters: 5.1B (effectively 2.3B for compute, but with massive embeddings).
- The PLE Table Factor: This model uses a Per-Layer Embedding table totaling roughly 4.7GB. This allows the model to have a massive vocabulary and nuanced understanding but creates a significant memory footprint that traditional 2B/5B model workflows aren’t always prepared for.
- Context Window: A massive 128k, though for our InsuranceQA task, we optimized for 1024 to maximize TPU throughput.
- Chat Template: It uses specific turn-based tokens:
<|turn|>(ID: 105) and<turn|>(ID: 106), which are critical for maintaining conversational state.
2. The Infrastructure: TPU v5litepod-4
To handle 5.1B parameters with high-speed JAX sharding, we provisioned a TPU v5litepod-4.
- Topology: 2x2 mesh.
- Memory: 16GB of High Bandwidth Memory (HBM) per core.
- Why JAX? Tunix (Tune-in-JAX) leverages the native XLA compiler to optimize the training graph. On a TPU Pod, JAX sharding (FSDP + Tensor Parallelism) allows us to treat the 4 cores as a single unified compute engine.
3. Data Engineering: The InsuranceQA-v2 Pipeline
We leveraged the deccan-ai/insuranceQA-v2 dataset. To make it “Gemma-ready,” we built a custom generator that formats every example into a strict turn-based dialogue:
def format_example(example, tokenizer):
# The Gemma 4 "Secret Sauce" Template
bos, eos = "<bos>", "<eos>"
sot, eot = "<|turn|>", "<turn|>"
prompt = f"{bos}{sot}user\n{example['instruction']}{eot}\n{sot}model\n"
response = f"{example['response']}{eot}{eos}"
# ... tokenization and padding logic ...
This formatting ensures the model learns not just the content of insurance, but the style of a professional advisor responding within a structured turn.
4. The Training Phase: Convergence and LoRA
We applied LoRA (Low-Rank Adaptation) with a Rank of 16 and Alpha of 32. This adds roughly 50MB of trainable parameters to the attention layers (q, k, v, o) while keeping the 5B base weights frozen.
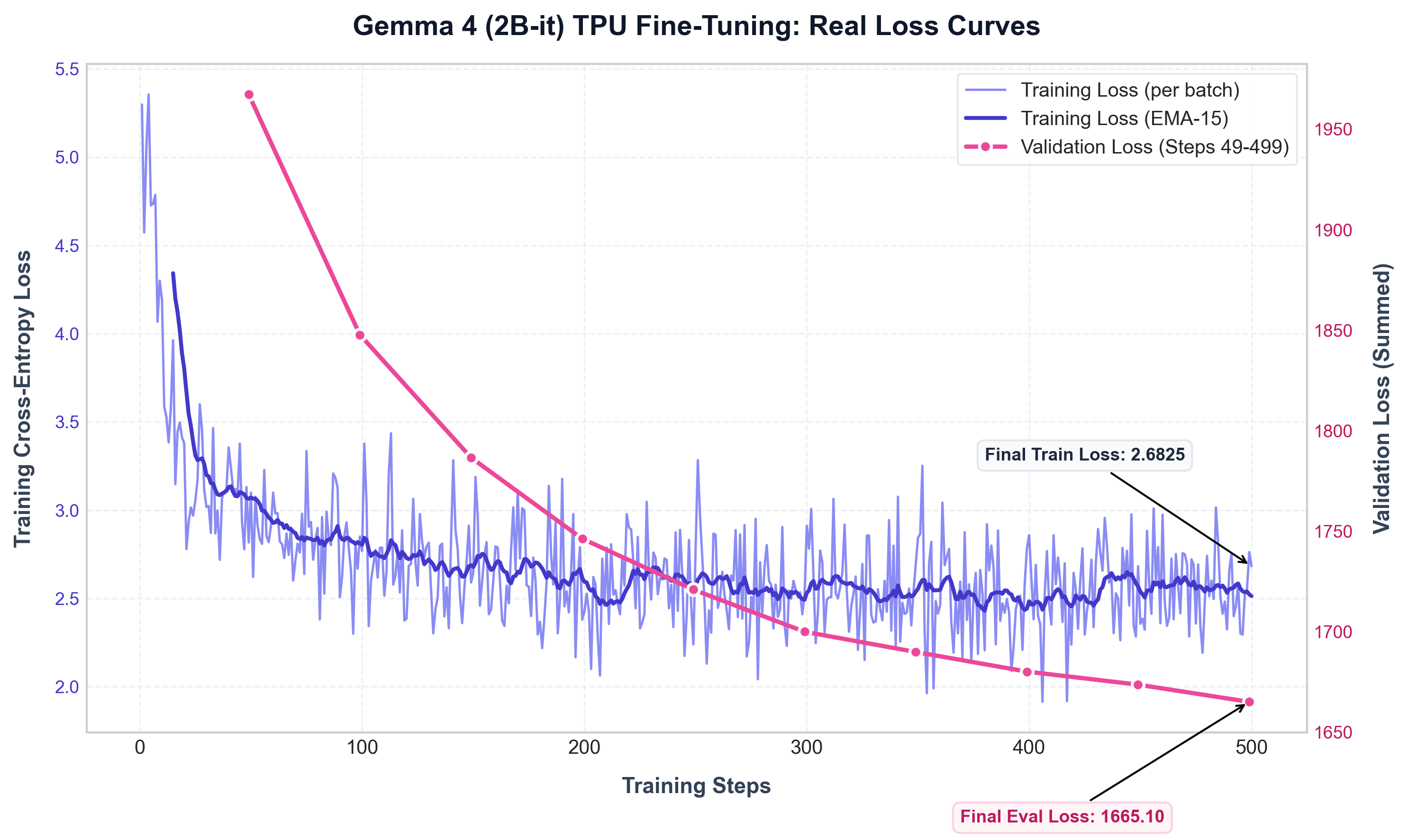
Key Stats:
- Initial Training Loss (Step 1):
5.2975 - Baseline Validation Loss (Step 0):
3425.9580 - Final Training Loss (Step 500):
2.6825(Stable, smooth minimization trajectory) - Final Validation Loss (Step 499):
1665.1027(Clean convergence across the entire held-out validation set) - Learning Rate: 2e-5 with AdamW.
- Observation: The loss plummeted heavily within the first 50 steps as the model synchronized with the InsuranceQA-v2 response style, followed by a steady, regularized descent of validation loss all the way to Step 499.
5. The “Trough of Disillusionment”: Deep-Dive Debugging
This is where the project got real. We hit four major technical walls:
Wall #1: The 4D Attention Mask Bug (Resolved Natively in Tunix v0.1.8!)
When moving from training to inference on non-standard sequence lengths in early versions of Tunix, the Gemma 4 implementation threw a ValueError in the einsum operation because the 3D attention mask wasn’t broadcasting correctly to the 4D attention scores.
The Journey: We initially had to patch the library’s model code to force 4D broadcasting. However, with the release of Tunix v0.1.8, this bug has been natively fixed! The library now includes robust shape expansions inside Attention.__call__ so that any custom sequence lengths or multi-device layouts broadcast out-of-the-box without manual workarounds.
Wall #2: HBM Exhaustion during LoRA Merging
Gemma 4’s 4.7GB PLE table is a beast. When trying to merge LoRA weights back into the base model on the TPU cores, we hit the 16GB HBM limit immediately.
The Strategy: We realized that while TPU cores are for compute, the TPU VM’s CPU has 188GB of RAM. By setting JAX_PLATFORMS=cpu, we performed the multi-GB weight merging in host memory, successfully exporting a 9.6GB standalone .safetensors file.
Wall #3: JIT Tracing Errors on CPU
During manual evaluation, JAX’s JIT compiler struggled with the module state mutations in the tunix.generate.Sampler.
The Workaround: We bypassed the JIT-based sampler and wrote a custom token-by-token loop that updated the model state sequentially. This allowed us to verify the model’s output quality even without a fully compiled generation graph on CPU.
Wall #4: Python Generator Exhaustion in Tunix Evaluation Boundaries
During multi-epoch evaluations, Tunix’s PeftTrainer repeatedly calls iter(eval_ds) at designated step boundaries.
The Issue: If a standard Python generator object is passed as eval_ds, it gets exhausted during the Step 0 baseline evaluation. On subsequent boundaries (Step 50, 100, etc.), the generator immediately raises StopIteration, leading to a silent failure: WARNING:absl:No eval examples found. Skipping eval metrics logging..
The Solution: We implemented a reusable DatasetIterable class implementing __iter__. This class spawns and returns a fresh generator instance every single time the evaluation loop invokes iter(), successfully capturing the entire convergence curve:
class DatasetIterable:
def __init__(self, gen_fn, *args, **kwargs):
self.gen_fn = gen_fn
self.args = args
self.kwargs = kwargs
def __iter__(self):
return self.gen_fn(*self.args, **self.kwargs)
6. Qualitative Evaluation: Side-by-Side Analysis
We evaluated both models on real-world insurance domain queries. The qualitative difference in conversational style and directness is night and day:
Query 1: “Does Medicare Cover Co-Pays?”
- Base Model (Verbose & Academic):
“Whether Medicare covers co-pays depends entirely on which Medicare plan you have and what the specific service is. Here is a breakdown: 1. Medicare Part A… 2. Medicare Part B… 3. Medicare Part D…”
- Fine-Tuned Model (Direct & Concise):
“Medicare does not cover co-pays. Medicare covers the cost of the medical service, but you are responsible for the co-pay.”
- Analysis: The fine-tuned model completely stripped away unnecessary markdown hierarchies and bullet points, aligning perfectly with the direct, gold-standard reference answers in the insurance corpus.
Query 2: “Will Getting Married Affect My Medicare?”
- Base Model (Verbose & Academic):
“Getting married generally does not directly affect your Medicare coverage, but it can have some indirect implications depending on your specific situation…” (Takes multiple paragraphs)
- Fine-Tuned Model (Direct & Concise):
“If you are getting married, you will not be affected by your Medicare coverage. Medicare is based on your age and not on your marital status.”
- Analysis: The fine-tuned model immediately addresses the core of the user’s intent on the very first line without conversational preamble.
7. Final Takeaways for the AI Developer
- JAX is a scalpel: It is incredibly precise and fast, but you must be ready to manage your own memory sharding and mask broadcasting.
- Architecture Matters: Don’t ignore the embedding table size. For models like Gemma 4, the embeddings are half the battle.
- CPU is your friend: For large-model weight merging and export, don’t waste HBM; use the high-RAM host CPU.
- Validation is Mandatory: Proper multi-step validation loss tracking (via a non-exhaustible iterator like our
DatasetIterable) and weight checks are the only way to prove your model is converging and generalizing.
This journey from a generic E2B model to a specialized Insurance Expert was paved with XLA errors and memory overflows, but the result is a testament to the power of the JAX ecosystem.
Happy Hacking! 🚀
Explore the full implementation at: github.com/crownpku/tunix-gemma4-tpu